|
ѕрактика применени€ Perl, PHP, Apache, MySQL дл€ активных Web-сайтов (—) јлександр ‘ролов, √ригорий ‘ролов, 2002 ќсновные операции с базами данных ”становка соединени€ с сервером —”Ѕƒ ќбработка результатов выполнени€ команды SQL оманды изменени€ таблиц базы данных ѕросмотр содержимого таблицы в сценарии PHP ќбычна€ техника использовани€ шаблонов —пециальные методы класса Template –едактирование и просмотр дерева ѕриложение дл€ редактировани€ дерева —ценарии PHP редактировани€ дерева –едактирование заголовка и текста узла ѕриложение дл€ просмотра дерева
—ценарии PHP никогда бы не приобрели большой попул€рности, если бы в них не было предусмотрено никаких средств работы с базами данных. счастью, PHP-приложени€м доступен простой и удобный набор функций интерфейса с —”Ѕƒ MySQL. —в€зка PHP-MySQL представл€ет собой отличную платформу дл€ создани€ Web-приложений как в среде операционной системы Linux, так и в среде Microsoft Windows. „то же касаетс€ доступа к —”Ѕƒ других типов, то здесь дела обсто€т не так хорошо, как в программах Perl. ¬ то врем€ как программам Perl доступна обширна€ библиотека модулей CPAN, включающа€ драйверы практически всех наиболее попул€рных баз данных, сценарии PHP вынуждены обходитьс€ только —”Ѕƒ тех типов, которые были встроены в интерпретатор PHP. ќднако в большинстве случаев указанный недостаток не играет особой роли, так как подавл€ющее большинство довольно сложных Web-приложений можно реализовать с применением бесплатной —”Ѕƒ MySQL. ¬ этой главе мы рассмотрим применение функций PHP, предназначенных дл€ доступа к MySQL, при решении наиболее типичных задач, встающих перед разработчиком Web-приложений. ќсновные операции с базами данных ѕрежде чем приступить к работе с базой данных, сценарий PHP должен установить соединение с сервером —”Ѕƒ и выбрать нужную базу данных в качестве текущей. ƒалее можно выдавать к выбранной базе данных запросы SQL и получать результаты их выполнени€. ¬ частности, можно создавать и обновл€ть таблицы, выбирать из них нужные записи в соответствии с заданным критерием и т.д. ѕеред завершением своей работы сценари€ PHP необходимо закрыть установленное ранее соединение с сервером —”Ѕƒ. –асскажем обо всем этом подробнее. ”становка соединени€ с сервером —”Ѕƒ —ценарий PHP может установить соединение с сервером MySQL двух типов Ч обычное и перманентное (посто€нное). ќбычное соединение закрываетс€ автоматически при завершении работы сценари€ PHP, а перманентное сохран€етс€ дл€ повторного использовани€ другими сценари€ми, запускаемыми на том же сервере. Ёто повышает производительность работы Web-приложени€ при большом количестве посетителей в единицу времени. „тобы установить обычное соединение с сервером MySQL, необходимо использовать функцию mysql_connect: resource mysql_connect ([string server [, string username [, string password]]]) ¬ качестве первого параметра функции mysql_connect передаетс€ доменное им€ или адрес IP узла, на котором запущен сервер MySQL. ≈сли Web-сервер и сервер —”Ѕƒ работают на одном и том же узле, то адрес сервера MySQL может быть указан как localhost. ѕри необходимости ¬ы можете задать стандартный или нестандартный порт дл€ доступа к серверу MySQL в виде такой строки: server='localhost:3306' ћожно также задать в первом параметре сокет домена Linux, на котором сервер MySQL воспринимает запросы, с помощью строки ":/path/to/socket". ¬торой и третий параметры функции mysql_connect задают, соответственно, идентификатор и пароль доступа к базе данных. «аметим, что все три параметра необ€зательные. ≈сли вызвать функцию mysql_connect без параметров, то будут использованы параметры по умолчанию. ¬ частности, дл€ первого параметра будет использовано значение localhost:3306, а дл€ второго Ч идентификатор пользовател€, запустившего сценарий. ƒл€ доступа к базе данных будет использован пустой пароль. — целью повышени€ устойчивости Web-приложени€ к Ђвзломуї, мы рекомендуем при настройке MySQL создать один или несколько идентификаторов пользовател€, наделив их минимально необходимыми правами, достаточными дл€ работы Web-приложени€. ƒл€ каждого такого пользовател€ следует указать свой пароль. ѕри успешной установке соединени€ функци€ mysql_connect возвращает идентификатор соединени€, а при неудаче Ч значение FALSE. ¬от пример подключени€ к базе данных trudogolik, рассмотренной нами ранее в главе 8 этой книги: $conn=mysql_connect("localhost", "trudogolik_adm", "admin"); ѕри возникновении ошибки в процессе подключени€ сценарий завершает свою работу при помощи функции exit. Ќиже мы рассмотрим более корректный способ обработки ошибок, возникающих при обращении сценариев PHP к базе данных. ƒл€ установки посто€нного соединени€ с сервером MySQL, необходимо использовать функцию mysql_pconnect: resource mysql_pconnect ([string server [, string username [, string password]]]) Ќазначение параметров и возвращаемое значение этой функции такие же, что и у только что рассмотренной функции† mysql_connect. огда сценарий PHP вызывает функцию mysql_pconnect, она провер€ет, было ли ранее установлено требуемое соединение. ≈сли соединение с указанной базой данных, идентификатором пользовател€ и паролем уже установлено, функц舆 mysql_pconnect возвращает идентификатор существующего соединени€, а не создает новое. Ќа этом экономитс€ врем€, что и приводит к повышению производительности Web-приложени€. ƒл€ того чтобы закрыть соединение, установленной функцией mysql_pconnect, сценарий PHP должен вызвать функцию mysql_close, о которой мы расскажем позже в этой главе. „тобы можно было устанавливать посто€нные соединени€ с сервером MySQL, интерпретатор PHP следует установить в сервере Apache как модуль, а не как программу CGI. ѕодробности ¬ы найдете в разделе ЂЌастройка Apache дл€ работы с PHPї предыдущей главы нашей книги. ѕри использовании PHP совместно с сервером Microsoft Internet Information Server следует установить PHP как расширение ISAPI (см. раздел ЂЌастройка Microsoft IIS дл€ работы с PHPї предыдущей главы). ѕримен€ть посто€нные соединени€ следует с осторожностью, так как они могут вызвать различные проблемы. Ќапример, если количество возможных соединений с —”ƒЅ ограничено, то рано или поздно все свободные соединени€ будут исчерпаны. ѕосле этого Web-приложение перестанет работать. “ака€ же ситуаци€ может по€витьс€ в результате наличи€ ошибок в сценари€х PHP, привод€щих к Ђповисаниюї открытых соединений или взаимным блокировкам таблиц. ѕосле установки соединени€ с базой данных сценарий PHP может выбрать базу данных в качестве текущей. ѕри этом все последующие команды SQL, выдаваемые с помощью функции† mysql_query, будут направл€тьс€ в выбранную базу данных (функци€ mysql_query будет рассмотрена в следующем разделе). «аметим, что существует и друга€ возможность Ч указывать базу данных непосредственно при выдаче команд. ¬ этом случае выбирать текущую базу данных не нужно, но дл€ работы с ней потребуетс€ использовать функцию mysql_db_query. Ёта функци€ отмечена в документации на PHP версии 4 как устаревша€ и не рекомендуема€ к использованию. „тобы выбрать текущую базу данных, следует вызвать функцию mysql_select_db: bool mysql_select_db(string database_name [, resource link_identifier]) ¬ качестве первого параметра функции mysql_select_db необходимо передать строку имени базы данных, котора€ должна стать текущей. ¬торой необ€зательный параметр задает идентификатор соединени€ с базой данных, установленного ранее функцией mysql_connect или mysql_pconnect. ≈сли этот параметр не указан, используетс€ то соединение, с которым сценарий PHP работал в последний раз. дл€ избежани€ трудно обнаруживаемых ошибок мы, однако, рекомендуем всегда указывать значени€ необ€зательных параметров подобного рода. ≈сли выбор данных произведен успешно, функци€ mysql_select_db возвращает значение TRUE, а при ошибке Ч значение FALSE. ¬от пример использовани€ функции mysql_select_db: if(!mysql_select_db("trudogolik",
$conn)) «десь мы делаем текущей базу данных с именем trudogolik. ¬ыдача команд SQL ак мы уже говорили, после выбора текущей базы данных к ней можно выдавать команды SQL при помощи функции mysql_query: resource mysql_query(string query [, resource link_identifier]) „ерез первый параметр этой функции передаетс€ строка запроса SQL, а через второй Ч идентификатор соединени€ с сервером базы данных. «аметим, что передаваема€ таким способом строка запроса SQL не должна завершатьс€ символом точка с зап€той. ≈сли строка SQL была выполнена без ошибок, функци€ mysql_query возвращает идентификатор ресурса, а если с ошибкой Ч значение FALSE. ¬от пример использовани€ команды mysql_query дл€ выборки всех записей таблицы city: $sql="SELECT id, title FROM
city"; јналогичным образом выдаютс€ и другие команды SQL. ќбработка результатов выполнени€ команды SQL —пособ дальнейшего использовани€ идентификатора ресурса, полученного от только что описанной функции mysql_query при успешном выполнении строки SQL, зависит от типа выполненной команды SQL. оманды изменени€ таблиц базы данных ≈сли выполн€лась команда изменени€ таблицы базы данных, така€ как DELETE, INSERT, REPLACE, или UPDATE, сценарий PHP может узнать количество строк таблицы, измененных в результате выполнени€ команды SQL. ƒл€ этого он может воспользоватьс€ функцией mysql_affected_rows: int mysql_affected_rows([resource link_identifier]) ¬ качестве параметра функции передаетс€ идентификатор установленного соединени€ с сервером базы данных. «аметим, что ¬ы не можете использовать функцию mysql_affected_rows дл€ анализа результатов выполнени€ команды SELECT. ƒл€ этой цели предназначена друга€ функци€, которую мы рассмотрим в следующем разделе. —уществует один особый случай Ч при удалении всех строк таблицы командой DELETE функци€ mysql_affected_rows вернет нулевое значение вне зависимости от количества удаленных строк. ≈сли при выполнении команды SQL возникли ошибки, функци€ mysql_affected_rows вернет значение Ц1. оманда SELECT ¬ результате выполнени€ команды SELECT из таблицы выбираютс€ строки, количество которых может измен€тьс€ от нул€ до полного количества строк в таблице. ‘ункци€ mysql_num_rows позволит ¬ам узнать, сколько именно строк было выбрано при выполнении команды SELECT: int mysql_num_rows(resource result) ¬ качестве параметра этой функции нужно передать значение, полученное от функции mysql_query. ƒл€ того чтобы получить строки, выбранные из таблицы в результате выполнени€ команды SELECT, следует использовать такие функции, как mysql_fetch_object, †mysql_fetch_array и аналогичные. ѕосле извлечени€ данных необходимо освободить ресурсы, полученные при выполнении команды, с помощью функции mysql_free_result. Ќиже мы привели прототип функции mysql_fetch_object: object mysql_fetch_object(resource result [, int result_type]) ¬ качестве первого параметра эта функци€ должна получить ссылку на ресурс, возвращенную функцией mysql_query при выполнении команды SELECT. ¬торой, необ€зательный параметр позвол€ет указать тип получаемого результата и дл€ этой функции обычно не указываетс€. ‘ункци€ mysql_fetch_object возвращает объект, свойствами которого €вл€ютс€ значени€ полей очередной строки результата. этим свойствам можно обращатьс€ по имени столбцов таблицы, что очень удобно. ¬ следующем разделе мы рассмотрим практическое применение функции mysql_fetch_object. ќписание остальных функций, предназначенных дл€ извлечени€ результатов выполнени€ команды SELECT, ¬ы найдете в документации, поставл€ющейс€ в составе дистрибутива интерпретатора PHP. ѕросмотр содержимого таблицы в сценарии PHP “еперь, когда мы описали основные функции PHP, предназначенные дл€ работы с базами данных MySQL, приведем пример простого сценари€, позвол€ющего просмотреть содержимое таблицы списка городов city из базы данных trudogolik. Ёта база данных была описана ранее в главе 8 с названием Ђ¬иртуальное кадровое агентство “рудоголик.–уї. ѕолный исходный текст сценари€ PHP ¬ы найдете в листинге 11-1. Ћистинг 11-1 ¬ы найдете в файле chap10\www.php.test\root\mysql\sample1\index.php на прилагаемом к книге компакт-диске. <html> ак видите, строки сценари€ PHP встроены непосредственно в текст документа HTML и раздел€ют его на два фрагмента. ¬ верхнем фрагменте документа сценарий, прежде всего, пытаетс€ установить соединение с базой данных при помощи функции mysql_connect: $conn=mysql_connect("localhost",
"trudogolik_adm", "admin"); “ак как Web-сервер работает на том же узле, что и сервер —”Ѕƒ, в качестве первого параметра мы передаем функции mysql_connect строку localhost. ќстальные два параметра задают, соответственно, идентификатор и пароль дл€ подключени€ к базе данных trudogolik. ≈сли по какой-либо причине соединение установить не удаетс€, сценарий записывает в текст формируемого документа HTML соответствующее сообщение об ошибке и завершает свою работу при помощи функции exit. Ќа следующем этапе сценарий выбирает базу данных trudogolik в качестве текущей базы данных, вызыва€ дл€ этого функцию mysql_select_db: if(!mysql_select_db("trudogolik",
$conn)) ¬ качестве первого параметра мы передаем функции mysql_select_db название базы данных trudogolik, а в качестве второго Ч идентификатор соединени€ с сервером MySQL, полученный от функции mysql_connect. ≈сли при выборе текущей базы данных возникает ошибка, то перед тем как завершить свою работу, сценарий закрывает соединение с базой данных при помощи функции mysql_close. ак мы уже говорили, это необ€зательна€ операци€, так как при завершении работы сценари€ все св€занные с ним ресурсы должны освобождатьс€ автоматически. “ем не менее, дл€ того чтобы не возникло проблем, св€занных с недостатком ресурсов из-за ошибок в программном обеспечении, мы рекомендуем ¬ам освобождать все ненужные ресурсы €вным образом. ƒалее, во втором фрагменте сценари€, при помощи функции mysql_query выдаетс€ команда SELECT: $sql="SELECT id, title FROM
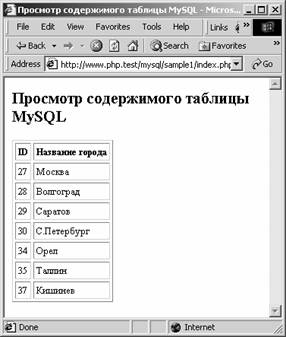
city"; ¬ыборка результата выполнени€ этой команды и оформление его в виде строк таблицы выполн€етс€ в цикле при помощи функции mysql_fetch_object, описанной ранее: while($row=mysql_fetch_object($result)) ќбратите внимание, что дл€ получени€ значений из полей id и title мы обращаемс€ к соответствующим свойствам объекта row. Ётот объект представл€ет собой очередную строку результата выполнени€ запроса, извлеченную функцией mysql_fetch_object. ѕеред завершением своей работы сценарий освобождает ресурсы, полученные дл€ хранени€ результата выполнени€ команды SELECT, а затем закрывает соединение с сервером базы данных: mysql_free_result($result); ¬нешний вид страницы, созданной только что описанным сценарием, показан на рис. 11‑1.
–ис. 11-1. ѕросмотр содержимого таблицы средствами PHP ак правило, все функции MySQL возвращают признак, по которому можно судить об успехе их выполнени€. ќднако чтобы получить расширенную информацию об ошибках, нужно использовать другие, специально предназначенные дл€ этого функции. ‘ункци€ mysql_error возвращает текстовое описание ошибки: string mysql_error([resource link_identifier]) ≈сли она вызываетс€ без параметров, то возвращает строку сообщени€ дл€ только что выполненной функции MySQL. ѕри необходимости ¬ы можете передать ей в качестве единственного параметра идентификатор соединени€, дл€ которого нужно получить сообщение об ошибке. ≈сли провер€ема€ функци€ MySQL завершилась без ошибок, функци€ mysql_error возвращает пустую текстовую строку. — помощью функции mysql_errno, вызываемой аналогично только что рассмотренной функции mysql_error, можно получить числовой код ошибки: int mysql_errno([resource link_identifier]) ¬от пример использовани€ функции mysql_error: if(!mysql_select_db("trudogolik",
$conn)) ѕрименение шаблонов HTML ¬ только что рассмотренном примере строки сценари€ PHP были встроены непосредственно в текст документа HTML. ак мы уже говорили, така€ техника оправдана только дл€ создани€ относительно простых Web-приложений, содержащих немного страниц. ≈сли же ¬ы занимаетесь разработкой сложных Web-проектов, рассмотрите возможность использовани€ шаблонов HTML. Ёто позволит отделить дизайн страниц от программного кода. ¬ этом разделе мы расскажем об использовании класса Template, описанного нами в предыдущей главе и предназначенного дл€ работы с шаблонами HTML, применительно к базам данных MySQL. ћы рассмотрим как обычную технику использовани€ шаблонов при решении задачи просмотра содержимого таблицы, так и методы, определенные в классе Template специально дл€ работы с базами данных MySQL. ќбычна€ техника использовани€ шаблонов ѕокажем, как можно сформировать страницу просмотра содержимого таблицы (рис. 11-1) с использованием классической техники шаблонов HTML. ƒл€ этого примера мы подготовили файл шаблона и файл со сценарием PHP. ¬ листинге 11-2 приведен исходный текст шаблона, предназначенного дл€ формировани€ страницы. ак можно заметить, в этом шаблоне нет ни одной строки программного кода PHP.
Ћистинг 11-2 ¬ы найдете в файле chap10\www.php.test\root\mysql\sample2\template.html на прилагаемом к книге компакт-диске. <html> ¬ начале файла шаблонов мы определили два условных шаблона с именами dberror1 и dberror2: <if NAME="dberror1"> Ёти шаблоны вступают в действие при возникновении ошибок, имеющих отношение к базе данных. ѕервый шаблон вставл€ет сообщение об ошибке, возникающей при подключении сценари€ к серверу —”Ѕƒ, а второй Ч при невозможности установить текущую базу данных. ƒалее следует еще один, третий условный шаблон с именем dbok: <IF NAME="dbok"> ќн используетс€ в том случае, если операции открыти€ соединени€ и выбора текущей базы данных прошли без ошибок. ¬нутри условного шаблона dbok находитс€ определение таблицы: <table border="1"
cellspacing="3" cellpadding="3"> ак видите, строки таблицы формируютс€ с помощью циклического шаблона city. ћы уже рассказывали ¬ам об использовании циклических шаблонов в предыдущей главе. ‘айл сценари€ PHP »сходный текст файла† сценари€ PHP, заполн€ющего только что описанный шаблон, приведен в листинге 11-3. Ћистинг 11-3 ¬ы найдете в файле chap10\www.php.test\root\mysql\sample2\index.php на прилагаемом к книге компакт-диске. <?php ¬ соответствии с поставленной задачей отделени€ дизайна страницы от программного кода, в файле сценари€ нет тегов HTML. ѕолучив управление, сценарий инициализирует переменные $dberror1, $dberror2 и $dbok: $dberror1=FALSE; Ёти переменные будут прив€заны к условным шаблонам, поэтому после такой инициализации все условные шаблоны будут в выключенном состо€нии. ƒалее сценарий открывает соединение с сервером базы данных: $conn=@mysql_connect("localhost",
"trudogolik_adm", "admin"); ≈сли при этом возникает ошибка, сценарий не завершает работу, как это было в предыдущем примере, а выводит в браузер посетител€ сформированное ¬ами сообщение об ошибке. “акое поведение сделает ¬аше приложение более профессиональным, так как оно не будет озадачивать посетителей непон€тными ему системными сообщени€ми. ќбратите внимание на префикс @, которым мы снабдили им€ функции mysql_connect. Ќапомним, что этот префикс отключает вывод системных сообщений об ошибках, которые лучше Ђспр€татьї от посетителей Web-узла, заменив более пон€тными и конструктивными сообщени€ми или рекомендаци€ми. ƒл€ заполнени€ шаблона мы использовали методы класса Template, описанные в предыдущей главе. ¬начале с помощью оператора new создаетс€ объект класса Template. ƒалее методом load_file загружаетс€ файл шаблона. ƒл€ заполнени€ циклического шаблона необходим метод parse_loop, а дл€ заполнени€ условного шаблона Ч метод parse_if. ѕодготовленный шаблон отправл€етс€ посетителю при помощи метода pprint. ѕродолжим описание сценари€. ¬ том случае, если сценарию удалось установить соединение с сервером базы данных, он выбирает текущую базу данных при помощи функции mysql_select_db: if(!mysql_select_db("trudogolik",
$conn)) ѕри возникновении ошибки в переменную $dberror2 заноситс€ значение TRUE, после чего соединение с базой данных закрываетс€. ƒалее сценарий выведет сообщение о невозможности выбора текущей базы данных в окно браузера. ≈сли же текуща€ база данных была выбрана успешно, сценарий выдает запрос SQL, выбира€ содержимое таблицы city с помощью команды SELECT: $dbok=TRUE; ѕосле этого сценарий извлекает результат запроса в цикле, заполн€€ циклический шаблон, как это показано ниже: $city = array(); »спользованна€ здесь техника заполнени€ шаблона была описана в разделе Ђ÷иклические шаблоныї предыдущей главы. ѕосле завершени€ цикла сценарий освобождает ресурсы, св€занные с выполнением запроса, при помощи функции mysql_free_result. ƒалее он отправл€ет заполненный шаблон в браузер посетител€. —пециальные методы класса Template “ак как огромное количество обращений к базам данных выполн€етс€ Web-приложени€ми с целью получени€ табличного результата, создатель класса Template предусмотрел специальные методы дл€ упрощени€ данной задачи. Ёто методы parse_sql и parse_pgsql. ѕервый из них предназначен дл€ —”Ѕƒ MySQL, а второй Ч дл€ —”Ѕƒ Postgre SQL, рассмотрение которой выходит за рамки нашей книги. ќсновна€ иде€ применени€ методов parse_sql и parse_pgsql, имеющих одинаковый набор параметров, состоит в прив€зке результата запроса SQL к циклическому шаблону <LOOP>. ¬ результате такой прив€зки отпадает необходимость в €вном заполнении циклического шаблона, которое мы делали в предыдущем примере. ѕо сравнению с предыдущим примером мы немного изменили файл шаблона (листинг 11-4). Ћистинг 11-4 ¬ы найдете в файле chap10\www.php.test\root\mysql\sample3\template.html на прилагаемом к книге компакт-диске. »зменени€ касаютс€ только циклического шаблона: <LOOP NAME="result"> ћы изменили им€, а также названи€ простых переменных шаблона дл€ заполнени€ столбцов. “еперь им€ циклического шаблона задано таким же, как и им€ переменной $result, хран€щей результат запроса. „то же касаетс€ названий простых переменных шаблона дл€ заполнени€ столбцов, то они такие же, что и соответствующие имена столбцов отображаемой таблицы city (а именно, id и title). ‘айл сценари€ PHP »сходный текст файла сценари€, заполн€ющего наш шаблон, ¬ы найдете в листинге 11-5. Ћистинг 11-5 ¬ы найдете в файле chap10\www.php.test\root\mysql\sample3\index.php на прилагаемом к книге компакт-диске. —равнива€ его с исходным текстом сценари€, описанного в предыдущем примере (листинг 11-3), мы отметим два важных отличи€. ѕервое касаетс€ способа обработки результата запроса: $conn=@mysql_connect("localhost",
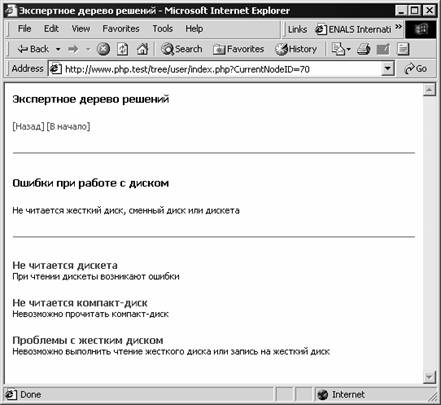
"trudogolik_adm", "admin"); ак видите, после выдачи команды SELECT сценарий закрывает соединение с базой данных, никак не обрабатыва€ полученный и хран€щийс€ в переменной $result результат выполнени€ этой команды. ќднако далее, при подготовке шаблона, сценарий вызывает метод parse_sql, передава€ ему в качестве второго параметра им€ переменной $result: $tpl = new template; ѕосле заполнени€ циклического шаблона результатами выполнени€ команды SELECT наш сценарий освобождает ресурсы, выделенный дл€ хранени€ результатов запроса, вызыва€ функцию mysql_free_result. «аметим, что эта функци€ вызываетс€ только в том случае, если в переменной $result действительно хранилс€ результат запроса. ≈сли же при установке соединени€ с сервером базы данных или при выборе текущей базы данных произошла ошибка, запрос к базе данных не выдавалс€. ѕоэтому в этом случае функцию mysql_free_result вызвать нет необходимости. ак видите, использование методов класса Template заметно упрощает обработку запросов SQL с командами SELECT. —окращаетс€ листинг программы и, следовательно, уменьшаетс€ веро€тность допущени€ ошибок при ее составлении. –едактирование и просмотр дерева ѕри создании сложных Web-приложений, таких, например, как »нтернет-магазины, каталоги и т.п часто встает необходимость работы с иерархически организованными структурами данных. Ќапример, каталог товаров »нтернет-магазина обычно имеет древовидную структуру. ƒл€ хранени€ иерархически организованных данных ¬ы можете использовать обычные рел€ционные таблицы, поэтому задача создани€, просмотра и редактировани€ деревьев может быть решена с использованием рассмотренных нами ранее методов работы с базами данных. ¬ этом главе мы расскажем об экспертном дереве решений, предназначенном дл€ оказани€ быстрой помощи пользовател€м компьютера, испытывающим трудности с аппаратным или программным обеспечением. ¬ узлах такого дерева наход€тс€ описани€ проблем. ќтвеча€ на вопросы и перемеща€сь по экспертному дереву от корн€ до вершины, пользователь выйдет на узел с описанием возможного решени€ проблемы. –азумеетс€, такое дерево можно использовать и дл€ решени€ проблем, не св€занных с компьютерами, например, медицинских. ¬ этом случае по симптомам заболевани€ можно быстро найти врача-специалиста, к которому следует обратитьс€ за помощью в данной ситуации. —траница просмотра нашего экспертного дерева, наполненного демонстрационными данными, показана на рис. 11-2.
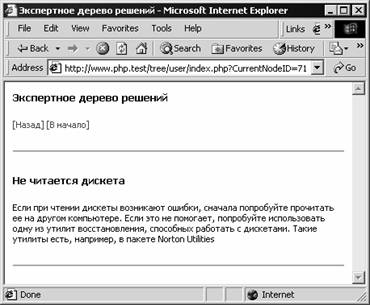
–ис. 11-2. ѕросмотр экспертного дерева решений — каждым узлом нашего дерева св€зано название и некоторый текст. орневой узел дерева называетс€ Ђѕроблемы с компьютеромї. —в€занный с этим узлом текст объ€сн€ет, как пользоватьс€ деревом дл€ решени€ проблем Ч достаточно просто выбирать нужные симптомы из списка, щелка€ ссылки, расположенные внизу страницы. ѕри этом ¬ы будете перемещатьс€ по дереву. Ќапример, если ¬ы полагаете, что проблемы св€заны с диском, щелкните ссылку ќшибки при работе с диском (рис. 11-2). ѕри этом в окно браузера будет загружено содержимое узла дерева со списком возможных проблем, имеющих отношение к дисковой пам€ти компьютера (рис. 11-3). —сылки [Ќазад] и [¬ начало] позвол€ют, соответственно, перейти к просмотру родительского и корневого узла.
–ис. 11-3. ѕросмотр узла Ђќшибки при работе с дискомї ƒостигнув конца ветви, ¬ы увидите текст рекомендаций по решению данной проблемы. Ќапример, если проблема про€вл€ет себ€ таким образом, что ¬ы не можете прочитать дискету, щелкните ссылку Ќе читаетс€ дискета (рис. 11-3). ѕосле этого в окне браузера по€витс€ текст с рекомендаци€ми на этот случай (рис. 11-4).
–ис. 11-4. –екомендации в случае, если не читаетс€ дискета ¬ табл. 11-1 мы привели структуру таблицы experttree, хран€щей данные нашего экспертного дерева. «аписи этой таблицы соответствуют узлам дерева. “аблица 11-1. “аблица experttree
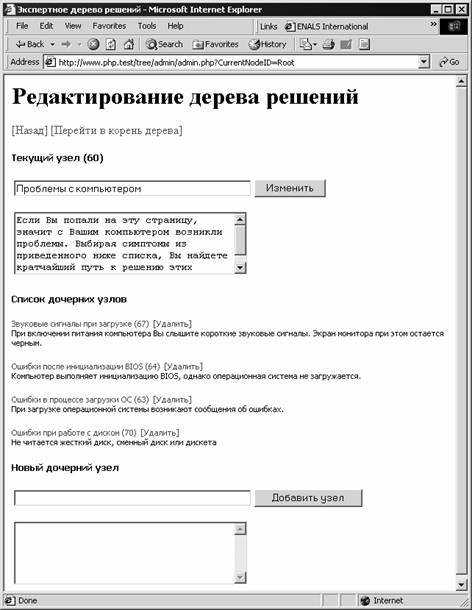
ак видно из этой таблицы, каждый узел дерева имеет свой уникальный идентификатор id. ƒл€ организации обратных ссылок по дереву мы храним идентификаторы родительских узлов в поле ParentNodeID. ” корневого узла в этом поле хранитс€ нулевое значение, не €вл€ющеес€ идентификатором ни одного другого узла. «аметим, что каждый узел дерева может иметь несколько дочерних узлов. ѕоэтому в таблице experttree могут существовать группы записей, имеющих одинаковые значени€ пол€ ParentNodeID. ¬ то же врем€ мы допускаем существование только одного корневого узла. ѕол€ Title и Text Ч текстовые. ѕервое из них определ€ет заголовок узла, отображающийс€ в верхней части страницы просмотра содержимого узла. Ќапример, на рис. 11‑3 заголовком узла €вл€етс€ строка Ђќшибки при работе с дискомї, а на рис. 11-4 Ч строка ЂЌе читаетс€ дискетаї. ¬торое поле содержит текст с описанием симптомов (рис. 11-3) или рекомендаций (рис. 11-4) и отображаетс€ сразу после заголовка узла. Ќиже мы привели исходный текст сценари€ SQL, при помощи которого можно создать таблицу experttree: CREATE TABLE experttree ( ак видите, поле id €вл€етс€ уникальным и играет роль первичного ключа. ƒл€ него задан режим автоматического увеличени€ значени€ при добавлении записи в таблицу. ѕриложение дл€ редактировани€ дерева ƒл€ создани€ и редактировани€ дерева мы подготовили страницу, показанную на рис. 11-5. ак видите, она очень напоминает страницу просмотра дерева (рис. 11-2), но предоставл€ет дополнительные возможности.
–ис. 11-5. —траница редактировани€ дерева ¬о-первых, р€дом с заголовком узла в скобках отображаетс€ его числовой идентификатор, вз€тый из пол€ id. ¬о-вторых, на странице имеютс€ две формы, с помощью которых можно измен€ть заголовок и текст узла, а также создавать новые дочерние узлы дл€ текущего узла. », наконец, в третьих, при помощи ссылок [”далить] можно† уничтожить узел дерева, не имеющий дочерних узлов. «аметим, что наше приложение не реализует функцию перемещени€ дочерних узлов. ѕри необходимости ¬ы можете дополнить его этой функцией самосто€тельно. ѕри помощи ссылок [Ќазад] и [¬ начало] можно перейти к просмотру, соответственно,† родительского и корневого узла. —ценарии PHP редактировани€ дерева ¬ листинге 11-6 мы привели исходный текст сценари€ PHP, при помощи которого создаетс€ и отображаетс€ страница редактировани€ дерева, показанна€ на рис. 11-5. Ћистинг 11-6 ¬ы найдете в файле chap10\www.php.test\root\tree\admin\admin.php на прилагаемом к книге компакт-диске. –ассмотрим его в детал€х. ¬ начале файла сценари€ мы подключаем класс шаблонов, так как он необходим дл€ отображени€ страницы: include('class.template.inc'); ѕри запуске сценари€ ему методом GET передаетс€ номер отображаемого узла или строка ЂRootї, если нужно отобразить корневой узел дерева. ѕолучив управление, сценарий извлекает этот номер и сохран€ет его в переменной $CurrentNodeID: $CurrentNodeID=$HTTP_GET_VARS['CurrentNodeID']; ≈сли сценарию передаетс€ нулевой номер узла, он замен€етс€ строкой ЂRootї: if($CurrentNodeID == 0) ƒалее сценарий записывает значение FALSE в переменные, предназначенные дл€ обработки ошибок, возникающих при обращении к базе данных: $dberror1=FALSE; Ќа следующем этапе сценарий пытаетс€ установить соединение с сервером базы данных и сделать текущей базу данных datarecovery, содержащую таблицу с данными нашего дерева: $conn=@mysql_connect("localhost",
"trudogolik_adm", "admin"); ≈сли текуща€ база была выбрана без ошибок, сценарий формирует строку SQL, необходимую дл€ выбора просматриваемого узла дерева: if(!strcmp($CurrentNodeID,
"Root")) ƒл€ выборки корневого узла мы используем условие ParentNodeID=0, так как только корневой узел отмечен нулевым значением в поле ссылки на родительский узел. ¬ остальных случа€х в строке запроса используетс€ заданный номер узла. ƒалее запрос выполн€етс€ при помощи функции mysql_query: $result=@mysql_query($sql); огда сценарий запускаетс€ в первый раз и таблица с данными дерева пуста€, мы выполн€ем начальную инициализацию, создава€ корневой узел дерева: if(!@mysql_num_rows($result)
&& !strcmp($CurrentNodeID,
"Root")) «десь мы просто создаем одну запись в таблице experttree, записыва€ в поле ParentNodeID нулевое значение. ѕол€ заголовка и текста, хран€щегос€ в узле, инициализируютс€, соответственно, строками Ђ'«аголовок корневого узлаї и Ђ'“екст корневого узлаї. ¬последствии ¬ы сможете отредактировать эти строки. ¬ том случае, когда таблица уже содержит записи, наш сценарий отображает их на странице при помощи шаблонов. ѕредварительно результат запроса извлекаетс€ при помощи функции mysql_fetch_object: $row=mysql_fetch_object($result); ƒалее сценарий получает список дочерних узлов текущего узла дл€ отображени€ в нижней части страницы редактировани€ дерева: $sql="SELECT id, Title, Text FROM
experttree WHERE ParentNodeID=$f_id"; ѕосле выполнени€ всех операций сценарий закрывает соединение с базой данных: @mysql_close($conn); ƒалее сценарий создает и отображает шаблон страницы: $tpl = new template; «десь используетс€ файл шаблона admin_template.html, исходный текст которого ¬ы найдете в листинге 11-7. Ћистинг 11-7 ¬ы найдете в файле chap10\www.php.test\root\tree\admin\admin_template.html на прилагаемом к книге компакт-диске. ¬ самом начале файла наход€тс€ простые шаблоны, предусмотренные дл€ отображени€ сообщений об ошибках при работе с базой данных: <if NAME="dberror1"> —разу после заголовка страницы в файле имеютс€ две ссылки ([Ќазад] и [ѕерейти в корень дерева]), перва€ из которых предназначена дл€ просмотра родительского узла, а втора€ Ч корневого узла дерева: <h1>–едактирование дерева
решений</h1> ƒл€ перехода к просмотру родительского узла вызываетс€ сценарий admin_goto_ParentNode.php, о котором мы расскажем ниже в этой главе, а дл€ перехода к просмотру корневого узла Ч только что рассмотренный сценарий admin.php. ѕри этом ему передаетс€ параметр CurrentNodeID со значением Root. ƒалее в файле шаблона расположена форма, с помощью которой можно отредактировать заголовок и текст данного узла: <h2>“екущий узел ({f_id})</h2> ак видите, редактирование выполн€етс€ сценарием admin_update_node.php, рассказ о котором также еще впереди. ѕомимо строк заголовка и текста узла этому сценарию через скрытые пол€ передаетс€ идентификатор обновл€емого узла. ѕродолжим изучение файла шаблона. ¬ нижней части файла располагаетс€ циклический шаблон, предназначенный дл€ отображени€ всех дочерних узлов данного узла: <h2>—писок дочерних
узлов</h2> ќбратите внимание, что в теле этого шаблона создаютс€ ссылки на сценарий admin_goto_node.php, предназначенные дл€ перехода к просмотру дочерних узлов, а также ссылки на сценарий admin_delete_node.php, предназначенный дл€ удалени€ узлов дерева. », наконец, в самом конце файла шаблона имеетс€ форма, предназначенна€ дл€ создани€ дочерних узлов в текущем узле дерева: <h2>Ќовый дочерний узел</h2> «десь дл€ создани€ дочернего узла вызываетс€ сценарий admin_create_node.php, которому помимо заголовка и текста узла передаетс€ идентификатор текущего узла. “еперь, когда мы рассмотрели основной сценарий, создающий и отображающий главную страницу редактировани€ дерева, перейдем к дополнительным сценари€м, вызываемым из этой страницы. —ценарий admin_goto_ParentNode.php нужен дл€ переход€ к просмотру узла, заданного своим идентификатором. »сходный текст этого сценарий приведен в листинге 11-8. Ћистинг 11-8 ¬ы найдете в файле chap10\www.php.test\root\tree\admin\admin_goto_ParentNode.php на прилагаемом к книге компакт-диске. »дентификатор узла, к просмотру которого необходимо перейти, передаетс€ сценарию методом GET через параметр ID. —ценарий сохран€ет этот параметр в переменной $form_ID: $form_ID=$HTTP_GET_VARS['ID']; ƒалее сценарий устанавливает соединение с сервером базы данных и выбирает в качестве текущей базу данных datarecovery: $dberror1=FALSE; $dberror2=FALSE; ƒалее сценарий выбирает из таблицы experttree идентификатор родительского узла дл€ узла с заданным идентификатором: $sql="SELECT ParentNodeID FROM
experttree WHERE id=$form_ID"; ≈сли в результате запроса не было найдено ни одной подход€щей записи, сценарий загружает в браузер страницу с содержимым корневого узла дерева: if(!@mysql_num_rows($result)) ¬ противном случае извлекаетс€ идентификатор родительского узла, который затем используетс€ дл€ загрузки при помощи сценари€ admin.php: else –едактирование заголовка и текста узла ƒл€ редактировани€ заголовка и текста узла используетс€ сценарий admin_update_node.php, исходный текст которого приведен в листинге 11-9. Ћистинг 11-9 ¬ы найдете в файле chap10\www.php.test\root\tree\admin\admin_update_node.php на прилагаемом к книге компакт-диске. ѕолучив управление, этот сценарий извлекает строки заголовка и текста узла, преобразу€ их при помощи функций trim и htmlspecialchars: $form_title=htmlspecialchars(trim($HTTP_POST_VARS['Title']),
ENT_QUOTES); ѕерва€ из этих функций удал€ет лишние пробелы в начале и на конце строк, а втора€ замен€ет специальные символы символьными объектами HTML. Ёто необходимо дл€ правильного отображени€ текста, содержащего кавычки, угловые скобки и другие специальные символы HTML. »дентификатор редактируемого узла сохран€етс€ в переменной $form_ID: $form_ID=$HTTP_POST_VARS['ID']; ƒалее наш сценарий устанавливает соединение с базой данных и обновл€ет содержимое нужной строки таблицы с помощью оператора UPDATE: $dberror1=FALSE; $dberror2=FALSE; ѕосле этого в браузер загружаетс€ содержимое обновл€емого узла: header("Location: admin.php?CurrentNodeID=$form_CurrentNodeID"); ƒочерни узел создаетс€ при помощи сценари€ admin_create_node.php, приведенного в листинге 11-10. Ћистинг 11-10 ¬ы найдете в файле chap10\www.php.test\root\tree\admin\admin_create_node.php на прилагаемом к книге компакт-диске. ѕрежде всего, сценарий извлекает заголовок и текст узла, а также идентификатор текущего узла, сохран€€ все это в соответствующих переменных: $form_title=htmlspecialchars(trim($HTTP_POST_VARS['title']),
ENT_QUOTES); ѕеред сохранением заголовок и текст узла обрабатываетс€ функци€ми trim и htmlspecialchars, о которых мы только что говорили. ƒалее сценарий открывает соединени€ с базой данных и добавл€ет запись в таблицу experttree с помощью оператора INSERT: $dberror1=FALSE; $dberror2=FALSE; ѕосле выполнени€ этой операции в окно браузера загружаетс€ текущий узел: header("Location: admin.php?CurrentNodeID=$form_CurrentNodeID"); ”даление выбранного узла дерева выполн€етс€ сценарием admin_delete_node.php (листинг 11‑11). «аметим, что этот сценарий удал€ет только узлы, не имеющие дочерних узлов. Ћистинг 11-11 ¬ы найдете в файле chap10\www.php.test\root\tree\admin\admin_delete_node.php на прилагаемом к книге компакт-диске. ѕолучив управление, сценарий извлекает идентификатор удал€емого узла и сохран€ет его в переменной $form_ID: $form_ID=$HTTP_GET_VARS['ID']; ƒалее он устанавливает соединение с базой данных и выбирает текущую базу данных: $dberror1=FALSE; $dberror2=FALSE; ≈сли эта операци€ была выполнена без ошибок, сценарий провер€ет наличие дочерних узлов у текущего узла. ƒл€ этого используетс€ запрос следующего вида: $sql="SELECT id FROM experttree
WHERE ParentNodeID=$form_ID"; ≈сли таблица не содержит узлов, у которых в качестве родительского в поле ParentNodeID указан удал€емый узел, выполн€етс€ удаление: if(!@mysql_num_rows($result)) ƒалее сценарий закрывает соединение с базой данных и загружает в браузер страницу, отображающую содержимое текущего узла: @mysql_close($conn); ѕриложение дл€ просмотра дерева ¬нешний вид страниц Web-приложени€, предназначенного дл€ просмотра экспертного дерева решений, был представлен ранее на рис. 11-2, 11-3 и 11-4. »сходные тексты этого приложен舆 во многом повтор€ют исходные тексты только что рассмотренного приложени€, позвол€ющего редактировать дерево. ¬ листинге 11-12 приведен исходный текст сценари€ PHP, предназначенного дл€ просмотра узлов экспертного дерева. Ћистинг 11-12 ¬ы найдете в файле chap10\www.php.test\root\tree\user\index.php на прилагаемом к книге компакт-диске. ƒл€ создани€ страницы просмотра мы используем шаблоны HTML, поэтому в начале файла сценари€ включаем определение класса class.template.inc: include('class.template.inc'); ѕолучив управление, наш сценарий извлекает методом GET идентификатор просматриваемого узла и сохран€ет его в переменной $CurrentNodeID: $CurrentNodeID=@$HTTP_GET_VARS['CurrentNodeID']; ≈сли значение этого идентификатора равно нулю, необходимо просмотреть корневой узел. ¬ этом случае мы замен€ем нулевое значение на строку Root: if($CurrentNodeID == 0) ƒалее сценарий устанавливает соединение с базой данных и выбирает текущую базу данных: $dberror1=FALSE; ¬ случае успеха этой операции сценарий формирует строку запроса SQL, выбирающую информацию о текущем узле и запускает ее на выполнение: if(!strcmp($CurrentNodeID,
"Root")) ѕолученные в результате выполнени€ запроса идентификатор, заголовок и текст узла сохран€етс€ в соответствующих переменных: $row=mysql_fetch_object($result); Ќа следующем шаге сценарий извлекает из базы данных список дочерних узлов текущего узла. $sql="SELECT id, Title, Text FROM
experttree WHERE ParentNodeID=$f_id"; ѕолученна€ информаци€ используетс€ дл€ заполнени€ шаблона HTML страницы просмотра содержимого узла template.html: $tpl = new template; »сходный текст только что упом€нутого шаблона ¬ы найдете в листинге 11-13. Ћистинг 11-13 ¬ы найдете в файле chap10\www.php.test\root\tree\user\template.html на прилагаемом к книге компакт-диске. ¬ начале файла наход€тс€ простые шаблоны, предназначенные дл€ отображени€ сообщений об ошибках при работе с базой данных: <if NAME="dberror1"> ƒалее следуют ссылки [Ќазад] и [¬ начало] на сценарии PHP, с помощью которых выполн€етс€ переход к просмотру родительского узла дерева и корневого узла дерева: <h2>Ёкспертное дерево решений</h2> ѕерва€ из этих задач решаетс€ с помощью сценари€ goto_ParentNode.php, который мы рассмотрим ниже в этой главе, а втора€ Ч с помощью ранее рассмотренного сценари€ index.php (листинг 11-12). Ќиже ссылок после разделительной черты располагаютс€ шаблоны заголовка и текста узла: <hr> », наконец, в самом низу файла имеетс€ циклический шаблон, с помощью которого на странице отображаетс€ список дочерних узлов текущего узла: <hr> ƒл€ перехода к просмотру дочернего узла здесь используетс€ сценарий goto_node.php, о котором мы расскажем ниже. »сходный текст сценари€ goto_node.php, предназначенного дл€ просмотра содержимого дочернего узла представлен в листинге 11-14: Ћистинг 11-14 ¬ы найдете в файле chap10\www.php.test\root\tree\user\goto_node.php на прилагаемом к книге компакт-диске. <?php ак видите, этот сценарий очень прост. ¬се, что он делает, это извлечение методом GET идентификатора дочернего узла и передача этого идентификатора сценарию index.php, осуществл€ющего просмотр содержимого узла. »сходный текст сценари€ goto_ParentNode.php, предназначенного дл€ просмотра содержимого родительского узла мы привели в листинге 11-15: Ћистинг 11-15 ¬ы найдете в файле chap10\www.php.test\root\tree\user\goto_ParentNode.php на прилагаемом к книге компакт-диске. —ценарий goto_ParentNode.php практически полностью повтор€ет аналогичный сценарий ранее рассмотренного в этой главе приложени€, предназначенного дл€ редактировани€ дерева (листинг 11-8), поэтому мы не будем повтор€ть его детальное описание. |
Ѕиблиотека
Ѕратьев
‘роловых
Ѕратьев
‘роловых