10. Связь Web-приложений с базами данных 10. Связь Web-приложений с базами данных Использование объекта Properties Работа с ADO в приложениях C++ Импортирование библиотеки типов ADO Обращение к интерфейсам и методам ADO Установка соединения с источником данных Обращение к интерфейсам и методам ADO Инициализация COM и переменных BSTR Установка соединения с источником данных Связь приложений с базами данных через OLE DB Подготовка параметров инициализации Получение описания набора записей Подготовка информации для привязки данных Исходный текст программы OLEDB Использование библиотеки шаблонов ATL Классы для работы с источником данных OLE DB Исходный текст программы ATLOLEDB Связь приложений с базами данных через ODBC Инициализация среды выполнения Инициализация среды для установки соединения Получение идентификатора команды Обработка результата выполнения команды Привязка полей к локальным переменным Извлечение диагностических записей Глобальные определения и константы Извлечение значений выходных параметров процедуры Исходный текст программы ODBCPARAM
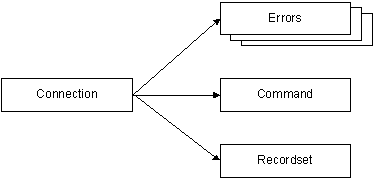
В предыдущих главах мы рассказывали о создании страниц HTML и ASP, отвечающих за интерактивное взаимодействие с пользователем через окно браузера. Теперь настало время обратиться к другому, не менее важному аспекту разработки приложений Web, — организации взаимодействия этих приложений с базами данных. Как мы уже говорили, существуют различные способы связи приложений с базами данных. На сегодняшний день наиболее передовой из них, несомненно, связан с применением интерфейса ActiveX Data Objects (ADO). Посредством этого интерфейса приложения (как обычные, так и ориентированные на использование технологий Интернета) могут подключаться к базам данных, извлекать, обрабатывать и обновлять информацию в базах данных. Кроме этого, для связи Web-приложений с базами данных может применяться объектный интерфейс OLE DB, программный интерфейс ODBC и другие средства. В десятой главе нашей книги мы рассмотрим применение интерфейсов ADO, OLE DB и ODBC для связи приложений ASP и программ, написанных на языке программирования C++, с базами данных, созданными на основе Microsoft SQL Server. Введение в ADO Возвращаясь к первой главе нашей книги, напомним, что для доступа к базам данных SQL Server можно использовать различные методы. Это программный интерфейс DB Library, программный интерфейс ODBC, объектный интерфейс RDO, объектный интерфейс OLE DB, и, наконец, объектный интерфейс ADO. ADO можно рассматривать как интерфейс уровня приложений, созданный поверх объектного интерфейса OLE DB. При этом интерфейс OLE DB обеспечивает универсальный доступ к данным. Такой доступ обеспечивается, в свою очередь, с помощью провайдеров, таких как Microsoft OLE DB Provider для ODBC (MSDASQL) или Microsoft OLE DB Provider для SQL Server (SQLOLEDB). Ключевыми элементами программной модели ADO является набор объектов, с помощью которых выполняется соединение с базами данных, выполнение команд с параметрами, получение результата выполнения этих команд в виде переменных или наборов записей, обработка событий и ошибок. Рассмотрим порядок обращения приложения к базе данных с применением программной модели ADO. · Установка соединения Прежде чем обращаться к базе данных, приложение должно установить соединение с сервером базы данных. Эта операция выполняется с помощью объекта Connection. Данный объект позволяет установить соединение с источником данных посредством интерфейса ODBC или непосредственно. В первом случае вам требуется указать имя источника данных Data Source Name (DSN), а во втором — информацию об источнике данных, такую как имя драйвера, имя сервера, пароль и т.д. В наших примерах мы будем использовать подключение к источнику данных с применением DSN. После завершения работы с соединением его необходимо закрыть, вызвав метод Close объекта Connection. · Подготовка команды и параметров После установки соединения приложение должно подготовить объект Command, записав в его свойства команды, необходимые для доступа к данным. Это могут быть команды выполнения строк языка Transact-SQL (например, строки «select * from clients»), команда вызова хранимой процедуры SQL Server по ее имени или имя таблицы. При помощи объекта Parameter приложение может передать вместе с командой параметры. Входные параметры позволяют передавать информацию в хранимые процедуры SQL Server, а выходные — принимать информацию из хранимой процедуры. · Выполнение команды Один из методов объекта Command с именем Execute предназначен для инициирования выполнения команды. В зависимости от выполняемой команды он может возвращать результат в виде набора записей Recordset или через выходные параметры хранимой процедуры (если команда запускает такую процедуру). · Обработка результатов выполнения команды Как мы только что говорили, результатом выполнения команды может быть набор записей, представляемых объектом Recordset. Например, в результате выполнения программы SQL «select * from clients» будет создан набор записей Recordset, представляющих собой массив строк таблицы clients. Приложение может просмотреть все записи из набора, сохранить их в своей локальной памяти или использовать каким-либо другим способом. В частности, можно обновить полученный набор записей с целью обновления источник данных (если это необходимо). После обработки набора записей его нужно закрыть методом Close, предусмотренным для этой цели в объекте Recordset. · Обработка ошибок В процессе подготовки параметров команды и ее выполнения могут возникать события, связанные с ошибками. Ваше приложение должно уметь их обрабатывать. Заметим, что одна команда может порождать несколько сообщений об ошибках, поэтому обработка должна выполняться в цикле. В этом разделе мы расскажем о методах и свойствах объектов, составляющих фундамент ADO. Попутно мы будем иллюстрировать применение этих методов в серверных сценариях ASP, составленных на JScript. При помощи объекта Connection приложение устанавливает связь с источником данных, то есть открывает сеанс связи с источником данных. Объект Connection связан с объектами Errors, Command и Recordset, как это показано на рис. 10-1.
Рис. 10-1. Объект Connection Из этого рисунка видно, что команды Command имеют отношение к вполне конкретному источнику данных, открытому для объекта Connection. Таким образом, Вы создаете объект Command для использования с выбранным источником данных. После успешного выполнения команды может быть создан набор записей Recordset. Этот набор тоже создается в контексте того сеанса связи с источником данных, которых был открыт в рамках объекта Connection. Если при выполнении команды возникли ошибки, создается объект Errors, представляющий собой набор (collection) объектов Error. Все эти объекты имеют отношение к конкретному объекту Connection и должны обрабатываться в его контексте. Рассмотрим маленький пример. Ниже мы привели фрагмент серверного сценария JScript, расположенного на странице ASP: var connect; В первой строке мы определили переменную connect, предназначенную для хранения объекта Connection. Далее мы создаем объект Connection, вызывая метод CreateObject объекта Server (объект Server является встроенным объектом ASP). Перед тем как установить соединение с источником данных, мы устанавливаем два свойства объекта Connection — таймаут сеанса ConnectionTimeout и таймаут выполнения команды CommandTimeout. Первое из них определяет время ожидания установления канала связи с источником данных (в секундах), а второе — время ожидания выполнения команды. Если таймаут истек, устанавливается состояние ошибки. Зачем мы устанавливаем эти параметры? Просто для того, чтобы сервер Web не выполнял бесконечное ожидание соединения или выполнения команды. Соединение будет оборвано также и в случае тяжелой загрузки сервера SQL Server, когда он не успевает справиться с поступающими запросами. Зная типичные времена выполнения команд, Вы можете в своем приложении выполнить соответствующую настройку таймаутов. Помимо свойств ConnectionTimeout и CommandTimeout, объект Connection имеет и другие свойства, определяющие параметры соединения. Однако пока мы ограничимся применением только этих свойств. Открытие канала связи с источником данных в нашем примере выполняется при помощи метода Open, определенного в интерфейсе объекта Connection. Мы передаем этому методу три параметра, определяющих имя источника данных, идентификатор пользователя и пароль, необходимые для получения доступа. Чтобы закрыть канал связи, используйте метод Close объекта Connection. Все неиспользованные каналы связи следует закрывать для экономии ресурсов сервера. В частности, сервер SQL Server может иметь ограниченное количество лицензий на соединения с клиентами. Если вовремя не закрывать неиспользуемые соединения, можно быстро исчерпать лимит таких лицензий, в результате чего приложение перестанет работать. Как мы уже говорили, объект Command необходим для выдачи команд в базу данных с целью проведения таких операций, как запуск хранимых процедур или исполнения строк программы Transact-SQL. Прежде всего, необходимо создать объект Command, обратившись для этого к методу CreateObject объекта Server: var cmd; Как видите, объект Command создается аналогично объекту Connection. После создания объекта Command необходимо установить как минимум три свойства этого объекта — ActiveConnection, CommandText и CommandType: cmd.ActiveConnection = connect; Сначала мы расскажем о свойстве ActiveConnection. Вы уже знаете, что любой объект Command имеет отношение к конкретному соединению Connection. Чтобы указать, что мы будем выдавать команду для источника данных, доступ к которому выполняется через соединение connect, нам необходимо записать ссылку на объект Connection в свойство ActiveConnection. Свойство CommandType задается как константа и определяет тип выполняемой команды. При этом назначение свойства CommandText полностью определяется типом команды, как это показано в табл. 10-1. Таблица 10-1. Константы типов команд
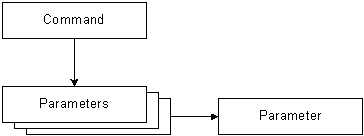
Чтобы выполнить строку программы SQL, такую как «select * from clients», следует записать в свойство CommandType константу adCmdText, а в свойство CommandText — строку программы SQL, например: cmd.CommandType = adCmdText; Выше мы приводили пример использования константы adCmdStoredProc для запуска хранимой процедуры. В наших приложениях мы будем выполнять все обращения к базе данных исключительно с применением хранимых процедур. Таким образом, в серверных сценариях, расположенных на наших страницах ASP, Вы не найдете ни одной строки SQL. Однако в разделе, посвященном вызову методов ADO в приложениях C++ мы приведем пример программы, непосредственно запускающей строку SQL, выполняющую выборку данных из таблицы. Сделаем небольшое отступление от темы и объясним, почему мы отказались от кодирования программ SQL непосредственно в серверных сценариях (хотя это вполне допустимо). Главным образом это объясняется стремлением отделить данные от программ. Сложные проекты обычно создаются группой разработчиков. При этом кто-то отвечает за дизайн страниц Web, кто-то разрабатывает сценарии ASP, а кто-то ведет базу данных. Отделяя данные от программ, мы позволяем разработчику базы данных не вникать в программирование серверных сценариев ASP. Создателю страниц ASP, в свою очередь, не требуется в совершенстве владеть языком SQL. Создавая интерфейс между приложением и базой данных на уровне хранимых процедур, мы разделяем задачи программирования сценариев и разработки базы данных, упрощая процесс разработки и сопровождения. С командой можно передать один или несколько параметров. Параметры передаются в виде набора Parameters, содержащего объекты Parameter (рис. 10-2).
Рис. 10-2. Набор Parameters В наших приложениях мы будем передавать параметры хранимым процедурам SQL Server, причем такие параметры будут как входные, так и выходные. Ниже приведен фрагмент программы серверного сценария JScript, создающий два входных параметра и один выходной: cmd.Parameters.Append(cmd.CreateParameter( В первой строке мы обращаемся к методу CreateParameter, определенному в объекте cmd класса Command (напомним, параметры имеют отношение к командам). Через первый параметр метода CreateParameter передается имя параметра команды cmd. В нашем случае это «User» — имя пользователя. Второй параметр метода CreateParameter определяет тип параметра команды cmd (строка, число, время, деньги и т.д.) и задается в виде константы. Мы передаем в хранимую процедуру имя пользователя типа varchar, поэтому тип параметра указан как adVarChar. Другие типы параметров приведены в табл. 10-2. Таблица 10-2. Константы для указания типов параметра команды
Третий параметр метода CreateParameter задает направление передачи данных через соответствующий параметр команды cmd. Параметры «User» и «Pass» входные, а «Rights» — выходной. Для обозначения входных параметров используется константа adParamInput. Выходные параметры обозначаются константой adParamOutput. Полный список констант направления передачи данных приведен в табл. 10-3. Таблица 10-3. Константы для указания направления передачи данных
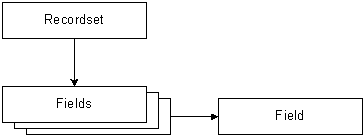
Через последние два параметра методу CreateParameter передаются, соответственно, размер области памяти, занимаемой параметром, и значение этого параметра. В нашем случае все параметры представляют собой текстовые строки размером не более 50 байт. Параметры «User» и «Pass» имеют значение «admin» и «adm_password», соответственно, а параметр «Rights» задается как символ пробела (это выходной параметр). После создания очередного параметра класса Parameter его нужно добавить в набор Parameters. Эта задача выполняется при помощи метода Append, определенном в объекте Parameters. В приведенном нами примере последовательно создаются и добавляются три параметра. Выходной параметр добавляется в два приема, хотя можно было бы создавать его таким же образом, что и входные параметры. Как получить значение выходных параметров после выполнения команды? Это делается простым обращением к свойству value параметра: cmd.Execute(); Здесь мы запустили на выполнение команду cmd, а затем получили значение выходного параметра (обработка ошибок опущена для простоты, мы опишем этот процесс позже). Хотя результатом выполнения хранимой процедуры может быть заполнение выходных параметров, чаще это бывает таблица, созданная вы результате выполнения строк SQL, расположенных в данной процедуре. Когда вы запускаете команду методом Execute, метод возвращает Вам объект Recordset, созданный в результате ее выполнения (конечно, если данная команда создает упомянутую выше таблицу). Объект Recordset является набором, состоящим из набора Fields. Набор Fields, в свою очередь, состоит из объектов Field (рис. 10.3).
Рис. 10-3. Набор Recordset Вы можете извлечь любую запись из набора Recordset, пользуясь набором Fields и объектом Field. Как это сделать? При создании объекта Recordset автоматически создается курсор, связанный таблицей, полученной в результате выполнения команды. Методы объекта Recordset позволяют определять тип курсора (предназначенный только для чтения, допускающий просмотр в одном направлении, статический, динамический, управляемый ключами), а также перемещать курсор для извлечения полей таблицы. Поясним сказанное на примере. Пусть нам нужно отобразить на странице ASP список книг, отобранных посетителем Интернет-магазина для покупки. Мы подготовили хранимую процедуру, получающую в качестве входного параметра имя клиента ClientID, и возвращающего список отобранных книг как результат выполнения запроса оператором SELECT: CREATE PROCEDURE ListOrders @ClientID
varchar(50) AS Данная процедура будет подробно рассмотрена позже. Сейчас нам важно только то, что она получает один входной параметр ClientID, а возвращает таблицу, содержащую пять столбцов таблицы books: booksID, Author, Title, Publisher и Price (это как раз тот интерфейс между приложением и базой данных, который нужен для отделения программы от данных). Для вызова хранимой процедуры ListOrders мы используем следующий фрагмент серверного сценария: var connect, rs, cmd, ClientID; Обратите внимание на последнюю строчку, где значение, возвращенное методом Execute, присваивается переменной rs. Эта переменная хранит объект Recordset, созданный в результате выполнения хранимой процедуры ListOrders. Мы знаем, что хранимая процедура ListOrders возвращает таблицу с пятью колонками. Для удобства обращаться к колонкам, мы определили в своем сценарии пять переменных: var fieldbooksID = 0; Теперь мы должны получить все строки возвращенной таблицы, передвигая курсор и обращаясь к объектам Field: %> Здесь мы создаем таблицу и записываем в ее ячейки содержимое полей текущей записи (на которую указывает курсор), обращаясь к четырем из пяти столбцов. Перемещение курсора на следующую запись выполняется методом MoveNext, определенным в объекте Recordset. Чтобы проверить условие завершения цикла, наш сценарий обращается к свойству rs.EOF. Таким образом, при каждом перемещении курсора мы получаем доступ к очередной строке таблицы, созданной в результате вызова хранимо процедуры ListOrders. Для извлечения содержимого отдельных полей текущей строки мы используем набор Fields. Элементы этого набора (представляющие собой объекты Field) соответствуют полям текущей строки: первый элемент (с индексом 0) соответствует первому столбцу (booksID), второй — второму и т.д. Заметим, что во многих случаях удобнее обращаться к полям набора записей не по номерам колонок, а по именам: <td><%=rs.Fields("Author")%>.
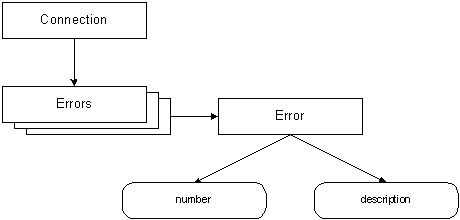
<%=rs.Fields("Title")%> Описанные здесь приемы работы с объектами Recordset будут использованы во всех примерах, приведенных в этой главе. При выполнении команд могут возникать ошибки. Ошибки попадают в ADO от провайдера и помещаются в набор Errors. Заметим, что в зависимости от ситуации в результате выполнения одной команды может возникать сразу несколько ошибок. Для каждой ошибки создается объект Error, который затем помещается в набор Errors. В случае серверных сценариев JScript объект Error имеет свойства number и description, первое из которых содержит числовой код ошибки, а второе — ее текстовое описание (рис. 10-4). Заметим, что в сценариях VBScript объект Error имеет несколько свойств, перечисленных в табл. 10-4. Эти же свойства доступны и в приложениях C++, обращающихся к объектам ADO с импортированием библиотеки типов. Таблица 10-4. Свойства объекта Error, доступные сценариям VBScript
Как видите, на сегодняшний день VBScript способен предоставить более обширную информацию об ошибках, чем JScript. Однако для решения большинства практических задач вполне достаточно средств обработки ошибок, предусмотренных в JScript.
Рис. 10-4. Набор Errors Набор Errors создается в рамках объекта Connection и имеет, таким образом, отношение к конкретному соединению с базой данных. Обработка ошибок заключается в том, что приложение в цикле перебирает все элементы Error набора Errors, выбирая из них код ошибки и текст сообщения об ошибке. Способ обработки ошибок в серверных сценариях ASP сильно зависит от языка, на котором этот сценарий был составлен. В литературе есть много примеров обработки ошибок в сценариях VBScript, но очень мало в сценариях JScript. Мы попытаемся восполнить этот недостаток. Как вы знаете, существует два принципиально разных подхода к обработке ошибок. Первый предполагает проверку кодов завершения при выполнении тех или иных операций, а второй основан на использовании исключений (exception). Исключения доступны практически во всех современных системах программирования. Например, такие операторы как try и catch встроены в C++ и Java. До недавних времен язык сценариев JScript был обделен возможностью обработки исключений, однако, начиная c JScript версии 5.0, ситуация изменилась. Рассмотрим следующий фрагмент кода, в котором выполняется обработка ошибок при использовании интерфейсов ADO: try Строки сценария JScript, в которых выполняется обращение к интерфейсу ADO, расположены в блоке try. Когда при вызове методов этих интерфейсов или просто в процессе выполнения сценария происходит ошибка, управление передается в блок catch. Заметим, что в сценарии JScript каждому блоку try может соответствовать только один блок catch, а не несколько, как в программах, составленных на языках C++ или Java. В качестве параметра в блок catch передается объект, содержащий информацию о возникшей ошибке. Если ошибка произошла при вызове методов интерфейсов ADO, этот объект имеет тип Error. Наш обработчик ошибок перехватывает только такие ошибки, передавая остальные системе интерпретации серверных сценариев ASP с помощью ключевого слова throw. Для проверки принадлежности переменной ex классу Error мы используем ключевое слово instanceof. На следующем этапе мы проверяем содержимое свойства Count объекта Errors. В нем находится счетчик объектов Error в наборе Errors, то есть, попросту говоря, количество ошибок. Если оно равно нулю, мы считаем, что произошла неожиданная ошибка, и передаем ее системе интерпретации серверных сценариев ASP. Далее мы в цикле перебираем все элементы набора Errors, формируя в текстовой переменной serrMessage итоговое сообщение об ошибке в формате фрагмента документа HTML. Это сообщение затем передается странице error.asp через параметр ERRMSG. Параметр ERROR мы используем для передачи имени страницы ASP, в которой произошла ошибка. Как лучше всего реализовать обработку подобных ошибок в приложении Web? Очевидно, пользователю не интересна развернутая диагностика ошибки, возникшей в Вашем приложении. Достаточно, если при возникновении подобной ситуации он получит абстрактное сообщение о том, что произошла внутренняя ошибка. При этом ему можно порекомендовать попробовать выполнить операцию еще раз через некоторое время. С другой стороны, информация об ошибках нужна Вам как разработчику приложения для его отладки и ликвидации возникших проблем. Поэтому можно попросить пользователя отправить вам диагностику по электронной почте, подготовив заранее форму с сообщением. А лучше если приложение будет автоматически записывать сообщения об ошибках в файл базы данных для последующего анализа. Можно, разумеется, комбинировать оба способа. Использование объекта Properties Объекты Connection, Command, Recordset и Field содержат в себе объекты Properties. Объект Properties представляет собой набор объектов Propertie, представляющих параметры объектов Connection, Command, Recordset и Field. Взаимосвязь этих объектов показана на рис. 10-5.
Рис. 10-5. Набор Properties Объекты ADO имеют встроенные и динамические объекты Properties. Первые реализуются в рамках ADO и доступны всегда, вторые обеспечиваются провайдером данных. В табл. 10-5 мы перечислили встроенные объекты Properties. Таблица 10-5. Встроенные объекты Properties
Практическое применение объектов Properties может найти, например, в случае необходимости определения или изменения времен таймаута или других параметров соединения. Но во многих случаях Вы вполне можете обойтись и без этого. Константы ADO При вызове некоторых методов ADO из серверных сценариев JScript необходимо указывать константы, определяющие, например, направление передачи данных через параметры или тип данных. Однако прежде чем использовать эти константы, необходимо позаботиться об их определении. Здесь можно предложить два способа. Первый способ заключается в том, чтобы включать в каждую страницу ASP, вызывающую методы ADO, специальный файл определения констант. После установки сервера SQL Server вы найдете этот файл в каталоге Program Files\Common Files\System\ado под именем adojavas.inc. Вот небольшой фрагмент, взятый нами из этого файла: . . . Однако данный подход может привести к некоторому замедлению интерпретации страниц сервером Web, так как файл adojavas.inc увеличивает количество строк сценария, подлежащих интерпретации. Лучшее решение заключается в импорте библиотеки типов ADO в файле global.asa, выполняемое с помощью тега METADATA с параметром TYPE="typelib": <!-- METADATA
TYPE="typelib" В результате импорта библиотеки типов ADO все константы, имеющие отношение к ADO, будут автоматически доступны во всех страницах Вашего приложения ASP. Изучая содержимое каталога Program Files\Common Files\System\ado, обратите внимание на подкаталог Docs. В нем находится подробный справочник по использованию ADO (на английском языке), подготовленный в формате HTML. В каталоге ADO вы также найдете файл adovbs.inc с определениями констант для серверных сценариев VBScript, а также текстовые файлы с описанием особенностей текущей версии ADO и другой полезной информацией. В следующей главе мы приведем примеры использования ADO для связи с базой данных в Web-приложении Интернет-магазина, а сейчас рассмотрим особенности обращения к базе данных через ADO в обычных программах, составленных на языке программирования C++. Работа с ADO в приложениях C++ Объектная модель ADO изначально рассчитана на возможность ее использования с различными языками и системами программирования, совместимыми с COM. В предыдущих разделах этой главы мы рассказали об использовании интерфейсов и методов ADO в серверных сценариях ASP, написанных на языке Microsoft JScript. Вместе с тем модель ADO также доступна в серверных сценариях VB Script, в программах Java, Microsoft Visual Basic и в приложениях, подготовленных при помощи Microsoft Visual C++. Такие языки программирования, как Microsoft JScript, VB Script и Microsoft Visual Basic в значительной степени скрывают от программиста тот факт, что работа с ADO выполняется средствами COM. Это позволяет разработчику составлять достаточно сложные программы, обращающиеся к базам данных, не затрудняя себя детальным изучением модели компонентных объектов COM. В случае использования C++ требуются более глубокие знания, хотя и здесь есть возможности для упрощения разработки приложений, интенсивно обращающихся к ADO. Для чего Вам может потребоваться создавать приложения C++, обращающиеся к базам данных посредством ADO? Если речь идет о приложениях для Интернета, то это нужно, прежде всего, для связи программных расширений сервера Web, таких как программы CGI или ISAPI, с базами данных. Кроме того, Вам может потребоваться расширить объектную модель ASP, добавив собственные элементы ActiveX, обращающиеся к базам данных. Разработчик приложения C++ может работать с ADO тремя различными способами: · непосредственный вызов интерфейсов и методов ADO с помощью функций программного интерфейса Win32, предназначенных для работы с COM; · применение средств библиотеки MFC, созданных для OLE; · импортирование библиотеки типов ADO помощью оператора #import. Первый из этих способов предполагает детальное знакомство программиста с методикой использования технологии COM. В частности, необходимо следить за использованием указателей на интерфейсы, своевременно захватывая их и освобождая при помощи методов AddRef и Release, а для создания объектов ADO приходится вызывать явным образом функцию CoCreateInstance. Второй способ, ориентированный на применение MFC OLE, упрощает работу с ADO посредством классов-оболочек (wrapper class). Недостатки данного способа — невозможность использования перечислимых типов данных из библиотеки типов ADO, а также необходимость поставлять вместе с программой библиотеку динамической загрузки MFC DLL. И, наконец, третий способ, основанный на включении библиотеки типов ADO оператором #import, предполагает создание вспомогательных классов оболочек, а также автоматическую генерацию перечислимых типов и глобальных уникальных идентификаторов GUID объектов ADO. Этот способ, на наш взгляд, наиболее удобен, так как позволяет получить примерно такую же простоту использования ADO в программах C++, какая достигается в сценариях JScript и VB Script. Одно из важных преимуществ использования оператора #import заключается в использовании так называемых интеллектуальных указателей (smart pointer) класса _com_ptr_t, а также классов для работы с типами данных BSTR и VARIANT. Интеллектуальные указатели позволяют не беспокоиться о реализации и вызове методов QueryInterface, AddRef и Release, упрощая работу с указателями на интерфейсы COM. Еще одна особенность, связанная с оператором #import — обработка ошибок при помощи исключений. Как известно, применение исключений для обработки ошибок вместо проверки кодов возврата сокращают объем листингов исходного текста приложений, упрощают разработку и отладку программ. Когда при создании объектов ADO или при выполнении методов ADO происходят ошибки, возникает исключение класса _com_error. Этот вспомогательный класс упрощает обработку ошибок, беря на себя работу по вызову методов интерфейса IErrorInfo. Импортирование библиотеки типов ADO Ранее мы уже пользовались технологией импортирования библиотеки типов ADO, создавая приложения ASP. Вспомните, что для каждого такого приложения мы создавали файл с именем global.asa, располагая его в корне виртуального каталога приложения. В области определения метаданных этого файла мы делали ссылку на библиотеку типов ADO следующего вида: <!-- METADATA
TYPE="typelib" Что же касается программ C++, то для импортирования библиотеки типов необходимо воспользоваться оператором #import, расположив его в области определений исходного текста программы: #import "d:\program files\common files\system\ado\Msado20.tlb" Наиболее подходящее место для расположения этого файла — файл StdAfx.h, создаваемый автоматически системой разработки Microsoft Visual C++ и содержащий включение в себя различных h-файлов. Разумеется, Вы можете включать оператор #import в файлы cpp, содержащие обращения к ADO. Как работает оператор #import? Когда компилятор встречает такой оператор, ссылающийся на ту или иную библиотеку типов, он генерирует для каждой библиотеки два текстовых файла с расширением имени tlh и tli. Например, при импортировании библиотеки типов ADO версии 2.0 создаются файлы с именами Msado20.tlh и Msado20.tli. Эти файлы создаются в каталоге с исходными текстами проекта Вашего приложения. Файл Msado20.tlh содержит определения объектов и перечислимых типов ADO, а файл Msado20.tli — классы-оболочки для методов объектной модели ADO. Вы можете просмотреть их содержимое при помощи любого текстового редактора, например, в окне редактирования Microsoft Visual C++. Если Вам не по душе идея размещения в исходном тексте программы абсолютных ссылок на файлы библиотек типов, можно воспользоваться другим вариантом вызова оператора #import: #import <Msado20.tlb> При этом, однако, необходимо чтобы полный путь к каталогу, содержащему библиотеку типов (в нашем случае это d:\program files\common files\system\ado) был прописан в переменной среды LIB, PATH или INCLUDE. Вместо этого можно добавить этот путь в список каталогов Visual C++ на вкладке Directories панели Options, вызвав ее на экран при помощи строки Options меню Tools (рис. 10-6).
Рис. 10-6. Добавление пути к каталогу с библиотекой типов ADO После импортирования библиотеки типов указанным выше образом может возникнуть проблема с константой EOF, определенной как значение –1. Эта константа обычно используется при работе с потоками ввода/вывода, однако как Вы скоро увидите, в ADO ей есть иное применение. Чтобы избежать конфликта имен, мы переименовываем EOF из библиотеки типов ADO в adoEOF, как это показано ниже: #import "d:\program files\common
files\system\ado\Msado20.tlb" \ Обращение к интерфейсам и методам ADO Прежде чем привести полные исходные тексты приложения, написанного на C++ и обращающегося к базе данных средствами ADO, рассмотрим основные приемы обращения к интерфейсам и методам ADO, основанные на использовании оператора #import. Инициализация COM Автономное приложение, работающее с объектами ADO, должно выполнить инициализацию системы COM перед началом своей работы вызовом функции CoInitialize. Перед тем как завершить работу, приложению необходимо освободить ресурсы, связанные с системой COM, при помощи функции CoUninitialize. Конечно, эти функции можно вызывать явным образом, однако удобнее определить глобальную структуру с конструктором и деструктором, выполняющую указанные действия: struct ComInit Установка соединения с источником данных Прежде чем обращаться к базе данных, приложение должно установить соединение с источником данных. Для этого потребуется объект Connection. В следующем фрагменте кода мы создаем объект Connection и записываем в переменную с именем cn указатель на интерфейс объекта: ADODB::_ConnectionPtr cn = NULL; Обратите внимание на то, как мы объявляем переменную cn. Здесь мы ссылаемся на пространство имен ADODB, определенное в результате импорта библиотеки типов ADO оператором #import. Тип _ConnectionPtr определен как указатель на интерфейс объекта Connection. Однако простое создание указателя еще не приводит к образованию объекта. Для того чтобы создать объект, мы вызываем метод CreateInstance, передавая ему в качестве параметра уникальный глобальный идентификатор GUID объекта ADODB::Connection. Этот идентификатор извлекается из файла Msado20.tli при помощи конструкции __uuidof, являющейся расширением C++, определенным в Microsoft Visual C++. Результат выполнения метода CreateInstance записывается в переменную hr типа HRESULT. Для проверки успеха завершения операции Вы должны использовать макрос SUCCEEDED, например: if(!SUCCEEDED(hr)) Здесь если операция завершилась с ошибкой, выполняется выход из функции установки связи с источником данных. Теперь, когда объект Connection успешно создан, можно открывать канал связи методом Open: _bstr_t bsConnString(L"DSN=BookStore"); Здесь мы передаем методу Open имя источника данных, имя и пароль пользователя, и дополнительный параметр, определяющий режим открытия (синхронный или асинхронный). Константа ADODB::adConnectUnspecified определяет синхронный режим, установленный по умолчанию. Асинхронный режим (задаваемый константой adAsyncConnect) в нашей книге не рассматривается. В процессе открытия канала связи с источником данных могут возникать ошибки, вызывающие исключения. Обработка этих исключений будет рассмотрена ниже. Обращаем Ваше внимание на класс _bstr_t. Он становится доступным в результате выполнения импорта библиотеки типов и помогает работать с типом данных BSTR. Тип BSTR используется в программировании элементов COM для передачи информации в виде текстовых строк Unicode. Класс _bstr_t облегчает создание таких строк и выполнение над ними основных операций. После завершения операций необходимо закрыть соединение с источником данных, вызвав метод Close: cn->Close(); Для того чтобы выполнить команду, пользуясь установленным соединением с источником данных, необходимо вызвать метод Execute: _bstr_t bsCommand(L"select * from
managers"); В качестве первого параметра мы передаем методу Execute строку команды. Как Вы помните, это может быть оператор языка SQL, имя хранимой процедуры или имя таблицы базы данных. В нашем случае выполняется оператор SELECT, выбирающий все данные из таблицы managers. Второй параметр метода Execute определяет параметры команды. В нашем случае параметры не используется, поэтому здесь мы указываем специальное значение vtMissing, отмечающее отсутствующий параметр. И, наконец, третий параметр метода Execute указан как константа ADODB::adCmdText. Эта константа определяет, что в первом параметре мы передали методу Execute строку SQL (а не имя хранимой процедуры или таблицы). После выполнения метод Execute возвращает указатель на интерфейс набора записей ADODB::_RecordsetPtr. Набор записей представляет собой таблицу, созданную в результате выполнения команды. Извлечение отдельных записей из набора необходимо выполнять в цикле. Здесь используется техника, аналогичная той, что была использована нами в сценариях JScript. Для проверки условия завершения цикла программа должна анализировать содержимое свойство EOF объекта Recordset: while(rs->adoEOF == VARIANT_FALSE) Здесь мы, однако, ссылаемся не на свойство EOF, а на переименованное при импорте библиотеки типов ADO свойство adoEOF. При достижении конца набора записей этой свойство будет содержать значение VARIANT_FALSE. Извлечение содержимого полей набора записей выполняется следующим образом: _variant_t vManagerID; Здесь мы ссылаемся на элемент набора Fields при помощи метода GetItem, передавая ему в качестве параметра имя столбца, в котором находится нужное нам поле (можно также задавать номер столбца, начиная с нуля). После извлечения очередной записи нужно передвинуть курсор на следующую запись набора Recordset, вызвав для этого метод MoveNext: hr = rs->MoveNext(); Извлеченные значения размещаются в переменных класса _variant_t. Ниже мы расскажем о том, как выполнить преобразование из этого типа в более привычные числовые и строчные типы данных. После завершения операций над набором записей Recordset его следует закрыть при помощи метода Close: rs->Close(); В этом разделе мы рассмотрим способ вызова хранимой процедуры с параметрами. Как мы уже говорили, использование хранимых процедур позволяет отделить данные от программ, что упрощает их создание и отладку. Чтобы передать хранимой процедуре параметры, Вы должны вначале создать объект класса Command (команду), а затем при помощи метода CreateParameter определить все необходимые параметры. Создание объекта Command выполняется так: ADODB::_CommandPtr cmd = NULL; Далее необходимо «привязать» команду к каналу связи с набором данных, установив значение свойства ActiveConnection: cmd->ActiveConnection = cn; Так как команда выполняет вызов хранимой процедуры, в свойство CommandType следует записать значение ADODB::adCmdStoredProc: cmd->CommandType = ADODB::adCmdStoredProc; В свойство CommandText Вы должны записать имя хранимой процедуры (как переменную класса _bstr_t): _bstr_t
bsCommandText(L"ManagerLogin"); Теперь займемся параметрами команды. Вначале нам нужно определить указатель на параметр как объект класса ADODB::_ParameterPtr: ADODB::_ParameterPtr param = NULL; Теперь мы создаем сам параметр, указывая его имя, тип, значение и размер данных: _bstr_t
bsParamName(L"User"); Здесь имя параметра задано как «User». Константа ADODB::adVarChar определяет, что параметр является текстовой строкой. С помощью константы ADODB::adParamInput мы указываем, что данный параметр является входным. Четвертый параметр метода CreateParameter указывает максимальный размер данных как –1, что означает отсутствие ограничений на этот размер. И, наконец, последний параметр, определяющий значение параметра, указан как vtMissing (то есть пропущен). Действительное значение входного параметра с именем «User» мы задаем при помощи метода Append: _variant_t vName(szName); Здесь мы вначале инициализируем переменную vName из обычной текстовой строки szName, закрытой двоичным нулем, а затем присваиваем ее значение свойству param->Value. Далее параметр добавляется в набор параметров методом Append. Второй входной параметр добавляется аналогично: _bstr_t
bsParamName1(L"Pass"); При создании выходного параметра мы используем константу ADODB::adParamOutput: _bstr_t
bsParamName2(L"Rights"); Далее команда запускается на выполнение (в нашем случае происходит запуск хранимой процедуры): cmd->Execute(&vtMissing, &vtMissing, ADODB::adCmdStoredProc); После ее завершения значение выходного параметра можно взять из свойства param->Value: _variant_t ok = param->Value; В начале этой главы мы рассказывали Вам о том, как выполняется обработка ошибок, возникающих при использовании объектов ADO. Как Вы знаете, ошибки попадают в ADO от провайдера и помещаются в набор Errors, приxем в результате выполнения одной команды может возникать сразу несколько ошибок. Для каждой ошибки создается объект Error, который затем помещается в набор Errors. Серверным сценариям JScript доступны только два свойства объекта Error —number и description, первое из которых содержит числовой код ошибки, а второе — ее текстовое описание. Программы C++ (так же как сценарии VB Script и программы, написанные на языке Microsoft Visual Basic) получают доступ ко всем свойствам объекта Error, перечисленным в табл. 10-4. Это Description (текст сообщения об ошибке), Number (код ошибки), Source (объект, вызвавший появление ошибки), SQLState (информация об ошибке от источника данных SQL), NativeError (аналогично SQLState), HelpFile (ссылка на файл справочной системы с объяснением ошибки) и HelpContext (идентификатор раздела справочной системы с описанием ошибки). Если программа C++ обращается к объектам ADO с применением импортирования библиотеки типов ADO посредством оператора #import, при возникновении ошибочной ситуации возникает исключение класса _com_error. Мы обрабатываем его с помощью конструкции try-catch следующего вида: try Обработка ошибок выполняется функцией AdoErrHandler, которой в качестве параметра cn передается указатель на интерфейс ADODB::Connection. В начале своей работы функция AdoErrHandler получает набор Errors, содержащий объекты Error, создаваемые для каждой ошибки: ADODB::ErrorsPtr Errors = NULL; Этот набор, извлекаемый с помощью метода GetErrors, мы будем обрабатывать в цикле, так как объектов Error может быть создано несколько. Для определения количества элементов в наборе Errors нужно использовать метод GetCount: long nErrCount; Далее извлечение объектов Error можно выполнить следующим образом: ADODB::ErrorPtr Error = NULL; Здесь переменная цикла i принимает значения от 0 до количества элементов в наборе Errors. С помощью метода GetItem мы по очереди извлекаем указатели на интерфейсы объектов Errors, сохраняя их в переменной Error типа ADODB::ErrorPtr. После использования указатель Error освобождается методом Release. Затем мы присваиваем ему значение NULL. Теперь для каждой ошибки (то есть для каждого извлеченного объекта Error) мы должны получить значения свойств. Эта операция выполняется с использованием методов, предусмотренных в объекте Error: CString strNumber; Здесь мы извлекли номер ошибки методом GetNumber, преобразовали его в текстовую строку и записали в строчную переменную strNumber класса Cstring. Аналогичные действия можно предпринять и для других свойств объекта Error: strDescription.Format("Description: %s", Полный текст функции обработки ошибок AdoErrHandler будет приведен ниже в листинге 4-57. В качестве примера приложения, написанного на C++ и обращающегося к ADO с применением импортирования библиотеки типов ADO, рассмотрим простую консольную программу просмотра записей таблицы managers из базы данных BookStore. Таблица managers содержит информацию о персонале Интернет-магазина, управляющего его работой через Интернет с помощью специального административного приложения. Назначение полей таблицы managers объясняется в таблице 10-6. Таблица 10-6. Поля таблицы managers
Когда сотрудник подключается к административному приложению, он вводит свой идентификатор и пароль. Приложение проверяет, есть ли такой пользователь в таблице managers и правильно ли указан пароль. Если все верно, приложение выбирает из поля Rights текстовое описание прав сотрудника и обновляет поле LastLogin, фиксируя момент его подключения к системе. Подробнее об использовании таблицы managers мы расскажем в следующей главе, а сейчас вернемся к нашей программе. При запуске программа запрашивает имя пользователя и пароль. Если ввести идентификатор пользователя, обладающего правами администратора, программа покажет полное содержимое таблицы managers: Login name: frolov Если же идентификатор или пароль введены неправильно, либо если данный пользователь не обладает правами администратора, то на консоли появляется лишь сообщение о запрете доступа: Login name: frolov Рассмотрим исходные тексты программы. Листинг файла stdafx.h, создаваемого автоматически системой разработки Microsoft Visual C++, мы не будем приводить ради экономии места. В этот файл мы добавили вручную строки импорта библиотеки типов ADO версии 2.0, как это показано ниже: #import "d:\program files\common
files\system\ado\Msado20.tlb" \ В листинге 10-1 приведен исходный текст самой программы. Листинг 10-1. Вы найдете в файле chap10\CPPADO\CPPADO.cpp на прилагаемом к книге компакт-диске. Глобальная переменная com_init класса ComInit предназначена для инициализации системы COM, а также для освобождения ее ресурсов, связанных с данной программой после завершения ее работы: struct ComInit Функция _tmain, получающая управление после запуска приложения, вызывает функцию login, определенную в нашей программе: int _tmain(int argc, TCHAR* argv[], TCHAR* envp[]) Функция login запрашивает с консоли идентификатор и пароль пользователя, ищет его в базе данных, извлекает и проверяет права. Если пользователь зарегистрирован и обладает правами администратора, функция login возвращает значение true, а если нет — false. Для администратора функция _tmain вызывает функцию getManagers, извлекающую из базы данных и отображающую информацию о сотрудниках магазина. Функция login Рассмотрим исходный текст функции login. В блоке try эта функция создает объект ADODB::Connection и открывает соединение: ADODB::_ConnectionPtr cn = NULL; Затем она запускает хранимую процедуру ManagerLogin, имеющую три параметра. В качестве двух входных параметров процедуре передается идентификатор пользователя и его пароль, а в качестве выходного возвращается строка с обозначением прав пользователя: ADODB::_CommandPtr cmd = NULL; Идентификатор и пароль запрашиваются из стандартного потока ввода, связанного с клавиатурой. Определение возвращаемого значения выполняется путем простого сравнения значения выходного параметра и текстовой строки «Administrator»: _variant_t ok = param->Value; Заметим, что оператор сравнения перегружен в классе _variant_t, поэтому такая операция выполняется очень просто. При возникновении ошибочных ситуаций управление передается в блок catch, где выполняется вызов функции обработки ошибок AdoErrHandler: try Так как ошибки привязаны к соединению с источником данных, в качестве параметра этой функции передается указатель на интерфейс нашего источника данных cn. Эта функция получает содержимое таблицы managers не с помощью хранимой процедуры, а выполняя строку SQL с оператором SELECT: ADODB::_ConnectionPtr cn = NULL; В результате выполнения этого оператора создается набор записей класса Recordset. Он обрабатывается в цикле с использованием приемов, описанных нами ранее: _variant_t vManagerID; Для преобразования полученных значений в текстовые строки и отображения их в консольном окне мы используем функцию v2str, исходный текст которой приведен в листинге 4-58. Исходный текст функции обработки ошибок AdoErrHandler приведен в листинге 10-2. Мы уже рассказывали раньше об использованных в нем приемах извлечения кодов ошибок. Листинг 10-2. Вы найдете в файле chap10\CPPADO\adoerrhandler.cpp на прилагаемом к книге компакт-диске. Служебная функция v2str (листинг 10-3) нужна для преобразования значений типа VARIANT в текстовые строки. Листинг 10-3. Вы найдете в файле chap10\CPPADO\vcrack.cpp на прилагаемом к книге компакт-диске. Эта функция получает входной параметр как ссылку на переменную класса COleVariant, предусмотренного в MFC для работы с переменными типа VARIANT. Результат преобразования возвращается как текстовая переменная класса CString. Функция v2str устроена очень просто. Как известно, переменная VARIANT может содержать значения разных типов, причем тип определяется содержимым поля vt. Функция v2str анализирует содержимое этого поля, выбирая тот или иной способ преобразования исходного значения в текстовую строку. Обратите внимание на применение функций COleCurrency и COleDateTime, помогающих выполнять такое преобразование для денежных данных и для значений дат: CString v2str(const COleVariant&
var) Эти функции доступны при использовании библиотеки классов MFC. Но при необходимости Вы сможете построить функцию, подобную v2str, и без применения средств MFC. Вызов ADO через функции Win32 Если Вам больше нравится вызывать интерфейсы элементов ActiveX с помощью программного интерфейса Win32, то Вы можете обойтись без импортирования библиотеки типов (хотя это более предпочтительный способ). В этом разделе мы расскажем о том, как обращаться к методам и свойствам объектов ADO без применения оператора #import. Обращение к интерфейсам и методам ADO Рассмотрим некоторые приемы обращения к интерфейсам и методам ADO, основанные на использовании функций программного интерфейса Win32, предназначенных для работы с объектами COM (таких как CoCreateInstance). Инициализация COM и переменных BSTR Как и в предыдущем случае, для работы с объектами ADO Вам необходимо проинициализировать систему COM вызовом функции CoInitialize, а перед завершением программы необходимо освободить ресурсы COM при помощи функции CoUninitialize. Отказавшись от импортирования библиотеки типов, мы не сможем воспользоваться для создания строк типа BSTR классом _bstr_t. Поэтому нам придется позаботиться об инициализации и освобождении ресурсов, связанных с такими строками. Эти операции удобно выполнять вместе с инициализацией и освобождением ресурсов COM в конструкторе и деструкторе специального объекта инициализации. Например, для инициализации строки параметров подключения к источнику данных мы вначале создаем глобальную переменную strAccessConnect типа CString и инициализируем ее следующим образом: CString strAccessConnect("DSN=BookStore;UID=dbo;PWD=;" ); Далее в конструкторе глобального объекта инициализации мы выделяем память для строки bstrAccessConnect и записываем в нее данные из строки strAccessConnect: BSTR bstrAccessConnect; Перед завершением работы программы деструктор объекта инициализации освобождает ресурсы, связанные со строкой bstrAccessConnect: SysFreeString(bstrAccessConnect); Установка соединения с источником данных Для установки соединения с источником данных нам необходимо создать объект Connection. Так как мы отказались от импортирования библиотеки типов ADO, нам придется выполнять эту операцию с помощью функции CoCreateInstance: #include <initguid.h> Обратите внимание, что для определения глобальных уникальных идентификаторов ADO, его классов и констант мы включили в исходный текст нашей программы файлы adoid.h и adoint.h. Файл initguid.h должен быть включен только в один файл Вашего проекта. Создавая объект Connection, функция CoCreateInstance записывает указатель на интерфейс этого объекта в переменную cn типа ADOConnection*. Результат выполнения операции сохраняется в переменной hr типа HRESULT. Так как при отказе от импортирования библиотеки типов ADO механизм обработки исключений _com_error от объектов ADO не используется, Ваше приложение должно проверять коды завершения вызываемых функций и методов. После создания объекта Connection необходимо открыть соединение. Для этого вначале нужно вызвать метод put_ConnectionString для записи строки параметров соединения, а затем вызвать метод Open, определенный в объекте Connection: if(SUCCEEDED(hr)) if(SUCCEEDED(hr)) Так как все параметры соединения устанавливаются методом put_ConnectionString, мы указали для первых трех параметров метода Open пустые значения bstrEmpty. Строка bstrEmpty определена как пустая строка: CString strEmpty(""); Последний параметр метода Open задает синхронный режим открытия канала связи с источником данных. Прежде чем выполнить команду, наша программа должна создать объект Command, вызвав для этого функцию CoCreateInstance: ADOCommand* cmd = NULL; В случае успеха ссылка на интерфейс команды записывается в переменную cmd типа ADOCommand*. Далее нам нужно установить связь между командой и каналом связи с источником данных, для которого эта команда будет выполняться. Эта операция выполняется с применением метода putref_ActiveConnection: if(SUCCEEDED(hr)) И, наконец, текст команды записывается методом put_CommandText: if(SUCCEEDED(hr)) В нашем случае будет исполняться команды выборки всех записей из таблицы managers. Переменная bstrCommand, содержащая эту команду, инициализируется следующим образом: CString strCommand("select * from
managers"); Теперь мы можем выполнять команду при помощи метода Execute: ADORecordset* rs = NULL; Параметр adCmdText указывает, что команда представляет собой строку программы SQL. В результате выполнения команды будет создан набор записей Recordset, причем указатель на интерфейс соответствующего объекта будет записан в переменную rs типа ADORecordset*. Как обычно, извлечение отдельных записей из набора необходимо выполнять в цикле. Для проверки условия завершения цикла программа должна вызывать метод get_EOF, определенный в объекте Recordset: VARIANT_BOOL bEOF = VARIANT_FALSE; При достижении конца набора записей этот метод вернет значение, равное константе VARIANT_FALSE. Цикл обработки набора записей может выглядеть, например, так: while(bEOF == VARIANT_FALSE) Здесь мы проверяем содержимое переменной bEOF, хранящей признак достижения конца набора записей, в начале тела цикла, а обновляем его в конце тела цикла после получения и обработки очередной записи. Проверку необходимо выполнить также и перед началом цикла (на случай, если в полученном наборе нет ни одной записи). Извлечение и обработка отдельных записей выполняется следующим образом. Вначале при помощи метода get_Fields мы получаем указатель на интерфейс набора Fields: ADOFields* adoFields = NULL; На следующем этапе мы вызываем через этот интерфейс методы get_Item и get_Value для каждого поля обрабатываемой записи: ADOField* fldManagerID = NULL; Здесь мы извлекли содержимое полей идентификатора сотрудника ManagerID и его имени Name. Чтобы перейти к обработке следующей записи набора, мы вызываем метод MoveNext: hr = rs->MoveNext(); Заметим, что отсутствие исключений заставляет нас выполнять проверку кода завершения каждого вызываемого метода, что увеличивает объем листинга. В этом разделе мы приведем несложный пример программы, обращающей к ADO без импортирования библиотеки типов. Эта программа, так же как и предыдущая, показывает в консольном окне содержимое таблицы сотрудников managers. Для сокращения листинга мы не стали проверять идентификатор и пароль пользователя, запускающего эту программу. Исходный текст программы вы найдете в листинге 10-4. Листинг 10-4. Вы найдете в файле chap10\CPPADO1\CPPADO1.cpp на прилагаемом к книге компакт-диске. Переменные strAccessConnect, strEmpty и strCommand класса CString предназначены для инициализации строчных переменных класса BSTR с именами bstrAccessConnect, bstrEmpty и bstrCommand, соответственно: CString
strAccessConnect("DSN=BookStore;UID=dbo;PWD=;" ); В строке bstrAccessConnect записана строка параметров, необходимых для подключения к источнику данных. Переменная bstrEmpty представляет собой пустую строку, а переменная bstrCommand содержит строку SQL, с помощью которой мы будем получать все записи из таблицы managers. Кроме того, нам потребуются две пустые переменные vtEmpty и vtEmpty2 класса VARIANT: VARIANT vtEmpty; В области глобальных переменных нашей программы находится определение переменной com_init класса ComInit, предназначенной для выполнения инициализации переда началом работы программы и для освобождения ресурсов перед ее завершением: struct ComInit В задачу конструктора класса входит вызов уже знакомой Вам функции CoInitialize, а также инициализация перечисленных выше переменных классов BSTR и VARIANT. Деструктор вызывает функцию CoUninitialize, а затем при помощи функции SysFreeString освобождает ресурсы, выделенные для строк класса BSTR. Отображение содержимого таблицы managers выполняется функцией getManagers, получающей управление от функции _tmain после запуска нашей программы и инициализации библиотеки классов MFC. int _tmain(int argc, TCHAR* argv[], TCHAR* envp[]) В области локальных переменных функции getManagers определены указатели на интерфейсы cn, rs и cmd: ADOConnection*cn = NULL; В переменную cn записывается указатель на интерфейс Connection, для чего используется функция CoCreateInstance, создающая объект указанного класса: HRESULT hr = S_OK; Если данный объект был успешно создан, мы записываем в свойство ConnectionString объекта Connection строку параметров соединения, вызывая для этого метод put_ConnectionString: if(SUCCEEDED(hr)) Далее соединение с источником данных открывается методом Open. Так как все параметры соединения уже записаны в свойство ConnectionString, мы указываем первые три параметра метода Open как пустые, передавая через них строку bstrEmpty: if(SUCCEEDED(hr)) На следующем этапе происходит создание объекта Command, для чего мы опять применяем функцию CoCreateInstance, но с другими параметрами. Указатель на интерфейс созданного объекта команд записывается в переменную cmd: if(SUCCEEDED(hr)) Чтобы связать объект Command и соединение, мы записываем указатель на интерфейс соединения в свойство ActiveConnection объекта Connection, вызывая метод putref_ActiveConnection: if(SUCCEEDED(hr)) Текст команды записывается методом put_CommandText в соответствующее свойство объекта Command: if(SUCCEEDED(hr)) Теперь можно выполнять команду, вызывая метод Execute. В качестве первых двух параметров мы передаем этому методу пустые переменные класса VARIANT. Третий параметр определяет, что необходимо выполнить строку SQL, заданную в свойстве CommandText объекта Command. И, наконец, через последний параметр методу Execute передается адрес переменной, в которую будет записан указатель на объект класса Recordset, содержащий набор записей, извлеченных из таблицы managers: if(SUCCEEDED(hr)) После выполнения команды мы выполняем в цикле извлечение отдельных записей набора Recordset, используя рассмотренную ранее методику, и выводим результат на консоль. Перед запуском цикла мы определяем переменные класса ColeVariant, в которые будут записаны значения, извлеченные из строк таблицы: COleVariant vManagerID; Кроме того, мы определяем рабочую переменную strTmp класса CString, а также переменную bEOF, которая будет использована для обнаружения конца набора записей: CString strTmp = ""; Далее мы извлекаем признак конца набора записей при помощи метода get_EOF: if(SUCCEEDED(hr)) В переменной adoFields будет находится указатель на интерфейс объекта Fields, с помощью которого мы будем извлекать записи из набора: ADOFields* adoFields = NULL; Следующие переменные предназначены для хранения указателей на интерфейсы объектов Filed, создаваемых для хранения содержимого отдельных полей текущей записи набора Recordset: ADOField* fldManagerID = NULL; Сам цикл организован следующим образом: while(bEOF == VARIANT_FALSE) В начале цикла мы получаем очередную строку набора записей, вызывая метод get_Fields для нашего набора записей. Затем мы по очереди извлекаем поля текущей записи методом get_Item, а затем и значения полей при помощи метода get_Value. Далее в цикле выполняется преобразование извлеченных значений в текстовую строку и вывод полученного результата на консоль. При этом используется функция v2str. Перед очередной итерацией цикла наша программа получает следующую запись набора, вызывая метод MoveNext. Сразу после этого извлекается признак достижения конца набора записей, который используется для проверки условия завершения цикла. После обработки всех извлеченных записей мы закрываем набор записей, а также соединение с источником данных: rs->Close(); Связь приложений с базами данных через OLE DB В предыдущих разделах этой главы мы рассмотрели практические приемы использования объектного интерфейса ADO в серверных сценариях ASP и в автономных приложениях Microsoft Windows, написанных на языке программирования C++. Как Вы смогли убедиться, и в том, и в другом случае применяются достаточно эффективные методы обращения к базам данных. Эти методы, не вызывают особых затруднений при реализации и отладке. Интерфейс автоматизации, определенный в рамках объектов ADO, позволяет обращаться к этим объектам из приложений, составленных практически на любом языке программирования, в том числе из языков сценария (таких, как JScript и VB Script). Мы также говорили, что объекты ADO представляют собой объектный интерфейс уровня приложений, созданный на базе другого объектного интерфейса, а именно OLE DB. Этот интерфейс представляет собой открытый стандарт, разработанный специально для предоставления доступа приложениям к базам данных, как реляционных, так и нереляционных (таких, как серверы почты, базы данных VSAM и т.д.). Создавая приложения OLE DB, Вы можете реализовать в нем как функции провайдера данных, так и функции потребителя данных. Заметим, что при создании приложений с базами данных в Интернете и в интрасетях в большинстве случаев применяют функции потребителя данных, используя какой-либо готовый провайдер (например, для интерфейса ODBC или для текстовых файлов). Необходимость в создании собственного провайдера может возникнуть лишь для обращений к нестандартной базе данных, поэтому в нашей книге мы не будем рассматривать этот случай. Применение объектного интерфейса OLE DB в большинстве приложений, созданных для Интернета, нам представляется необязательным, а в некоторых случаях и нежелательным. Фактически все операции с реляционными базами данных можно выполнять в рамках объектного интерфейса ADO. Именно эта технология, простая в применении и отладке, рассматривается Microsoft как наиболее современная и подходящая для создания приложений Интернета. Тем не менее, для того чтобы у Вас сложилась более полная картина, мы рассмотрим некоторые случаи реализации этого метода доступа в автономных приложениях Windows, написанных с использованием Microsoft C++. В рамках одной главы невозможно рассказать об объектах OLE DB хоть сколько-нибудь подробно, поэтому мы изложим только основы. Вы сможете применить полученные знания на практике, создавая, например, расширения сервера Web, обращающиеся к базам данных через OLE DB, в виде приложений CGI или ISAPI. Программная модель OLE DB Так же как и в случае только что рассмотренной объектной модели ADO, базовыми элементами программной модели OLE DB является набор объектов. Эти объекты применяются для установки соединения с базами данных и сеансов, выполнения команд с параметрами, получения результата выполнения этих команд в виде переменных или наборов записей, обработки событий и ошибок. Рассмотрим порядок обращения приложения к базе данных с применением программной модели OLE DB. · Инициализация среды выполнения Работа OLE DB основана на модели компонентных объектов COM, поэтому сразу после начала своей работы приложение должно выполнить инициализацию системы COM. Как правило, обычные приложения выполняют эту инициализацию вызовом функции CoInitialize. В результате становится возможным загрузка объектов провайдера OLE DB и работа c этими объектами. · Инициализация источника данных Прежде чем обращаться к данным, приложения OLE DB должно установить соединение с источником данных. Это действие требуется и при использовании метода доступа ADO, однако установка соединения с применением объектов OLE DB выполняется по-другому. Во-первых, для установки соединения приложение должно создать массив структур свойств, содержащих информацию для выполнения аутентификации. Как минимум требуется указать имя источника данных, имя пользователя и пароль. Во-вторых, приложение должно вызвать метод SetProperties интерфейса IDBProperties, выполняющий инициализацию указанных выше свойств. Интерфейс IDBProperties становится доступным после инициализации OLE DB. И наконец, в-третьих, приложению необходимо вызвать метод Initialize интерфейса IDBInitialize, что обязательно для инициализации источника данных. После завершения работы с соединением его надо закрыть, вызвав метод Uninitialize интерфейса IDBInitialize. Сеанс играет роль, аналогичную соединению с источником данных в ADO. В рамках сеанса приложение может выдавать команды, выполняя те или иные операции с источником данных. Для открытия сеанса приложение использует метод CreateSession интерфейса IDBCreateSession. · Подготовка команды и параметров При создании сеанса методом CreateSession интерфейса IDBCreateSession программа получает указатель на интерфейс IDBCreateCommand, позволяющий создавать команды. Устанавливая методом SetProperties интерфейса ICommandProperties различные атрибуты команды, программа влияет на ее исполнение. Далее необходимо задать текст команды. Эта операция выполняется методом SetCommandText интерфейса ICommandText. Текст команды представляет собой строку языка Transact-SQL, имя хранимой процедуры SQL Server или имя таблицы. При необходимости средствами метода Prepare интерфейса ICommandPrepare программа может выполнить предварительную подготовку команды. Эта операция имеет смысл, если команда представляет собой строку языка Transact-SQL (а не хранимую процедуру) и будет выполняться многократно. Если команда имеет параметры (например, команда запуска хранимой процедуры с параметрами), необходимо описать параметры команды, создав группу структур-описателей доступа, называемых Accessor. Для выполнения команды программа должна вызвать метод Execute интерфейса ICommandText. После этого необходимо освободить объект, использованный для выдачи команды. В результате выполнения команды может быть создан набор записей, состоящий из строк. По своему назначению этот набор записей аналогичен набору класса Recordset, создаваемый в приложениях ADO. · Обработка результатов выполнения команды Результаты выполнения команды OLE DB представлены наборами строк, отформатированными в виде таблицы. Для извлечения данных из набора Вы должны использовать ряд интерфейсов. Прежде всего, Вам потребуется интерфейс IColumnsInfo. С его помощью программа получит информацию о столбцах набора данных. Интерфейс IRowsetInfo обеспечивает программу информацией о самом наборе записей. С помощью интерфейса IAccessor программа выполнит привязку данных полученной таблицы к переменным, определенным в программе. И наконец, интерфейс IRowset нужен для получения данных из строк набора записей. Обычно при извлечении данных из набора записей приложение вначале вызывает метод CreateAccessor интерфейса IAccessor, выполняя привязку данных к переменным. Далее все записи набора извлекаются порциями в цикле с помощью метода GetNextRows интерфейса IRowset. А затем программа вызывает метод GetData интерфейса IRowset для получения данных из строк набора и записи этих данных в переменные, указанные в процессе привязки. Обработка ошибок, возникающих при применении методов OLE DB, намного сложнее, чем обработка ошибок, связанных с использованием ADO. Ошибки могут возникать при создании многочисленных объектов OLE DB, поэтому Ваше приложение должно проверять код завершения соответствующих функций. Если метод какого-либо интерфейса завершился с ошибкой и вернул соответствующее значение, необходимо его проанализировать. При этом Вам потребуются интерфейсы ISupportErrorInfo, IErorInfo, IErrorLookup, IErrorRecords и ISQLErrorInfo. В таблице 10-7 кратко описаны перечисленные интерфейсы. Таблица 10-7. Интерфейсы, связанные с обработкой ошибок
Использование объектов OLE DB Для работы с OLE DB Ваше приложение должно создать ряд объектов OLE DB, а затем обращаться к методам и свойствам этих объектов. Ниже мы рассмотрим некоторые методы и свойства важнейших объектов OLE DB, необходимые для создания автономных приложений C++, выполняющих запросы к базам данных. Для установки соединения с источником данных Ваша программа должна создать объект SQLOLEDB, предоставляющий интерфейсы источника данных, а затем выполнить его инициализацию. Создание объекта SQLOLEDB Для создания этого объекта необходимо воспользоваться функцией CoCreateInstance, вызвав ее следующим образом: IDBInitialize* pIDBInitialize = NULL; Здесь через первый параметр мы передаем функции CoCreateInstance константу CLSID_MSDASQL, содержащую идентификатор класса SQLOLEDB. Третий параметр функции CoCreateInstance, заданный с помощью макрокоманды CLSCTX_INPROC_SERVER, определяет, что источник данных SQLOLEDB работает как встраиваемый в процесс сервер (in-process server). Четвертый и пятый параметры задают соответственно идентификатор интерфейса IDBInitialize и адрес переменной pIDBInitialize, в которую записывается указатель на интерфейс IDBInitialize. Если объект создан успешно, значение SUCCESS(hr) будет равно true. В этом случае Ваша программа может продолжить работу с источником данных, выполняя его инициализацию и создание сеанса. После завершения работы с источником данных программа должна вызвать метод Uninitialize объекта SQLOLEDB, воспользовавшись для этого интерфейсом IDBInitialize: pIDBInitialize->Uninitialize(); Далее программа освободит ненужный более указатель на интерфейс IDBInitialize, вызвав метод Release: pIDBInitialize->Release(); Подготовка параметров инициализации Для инициализации источника данных нам нужно создать массив структур DBPROP, элементы которого будут содержать параметры инициализации (свойства объекта SQLOLEDB). Структура DBPROP определена следующим образом: typedef struct
tagDBPROP Ее поля описаны в таблице 10-8. Таблица 10-8. Поля структуры DBPROP
Возможные значения, устанавливаемые провайдером источника данных в поле dwStatus, перечислены в таблице 10-9. Таблица 10-9. Значения поля dwStatus
Итак, для инициализации соединения с источником данных нам нужен массив структур DBPROP, элементы которого описывают свойства источника данных. В простейшем случае требуется задать четыре свойства: · уровень приглашения, определяющий, нужно ли выводить на экран приглашения для пользователя; · имя источника данных DSN; · имя пользователя; · пароль пользователя для доступа к источнику данных. Для хранения этих свойств мы создаем массив rgInitProperties из четырех элементов: DBPROP rgInitProperties[4]; Далее нужно выполнить инициализацию элементов массива rgInitProperties. В поле dwPropertyID первого элемента массива (уровень приглашения) мы записываем константу DBPROP_INIT_PROMPT: rgInitProperties[0].dwPropertyID = DBPROP_INIT_PROMPT; Таким образом обозначается, что данный элемент массива будет содержать параметры свойства, определяющего уровень приглашения. Данное свойство имеет отношение ко всем столбцам, поэтому в поле colid мы указываем значение DB_NULLID: rgInitProperties[0].colid = DB_NULLID; Свойство, определяющее уровень приглашения, является обязательным (как и все остальные три свойства нашего массива). Поэтому в поле dwOptions указана константа DBPROPOPTIONS_REQUIRED: rgInitProperties[0].dwOptions = DBPROPOPTIONS_REQUIRED; Установка значения свойства выполняется в три приема: VariantInit(&rgInitProperties[0].vValue); Вначале инициализируется поле vValue, имеющее тип VARIANT, с помощью функции VariantInit. В результате такой инициализации в поле будет записано значение VT_EMPTY. Далее мы указываем в поле vt тип данных как VT_I2 (двухбайтовое целое со знаком), а затем записываем в поле iVal константу DBPROMPT_NOPROMPT. Эта константа указывает, что в процессе инициализации пользователю не следует выводить на экран никаких приглашений. Все возможные значения данного свойства перечислены в таблице 10-10. Таблица 10-10. Значения свойства DBPROP_INIT_PROMPT
Второй элемент массива rgInitProperties определяет имя источника данных. Идентификатор соответствующего свойства задается в поле dwPropertyID с помощью константы DBPROP_INIT_DATASOURCE: rgInitProperties[1].dwPropertyID = DBPROP_INIT_DATASOURCE; В поля dwOptions и colid этого и следующих двух элементов массива rgInitProperties мы записываем значения DBPROPOPTIONS_REQUIRED и DB_NULLID соответственно: rgInitProperties[1].dwOptions =
DBPROPOPTIONS_REQUIRED; Что же касается собственно имени источника данных, то оно записывается в поле vValue как строка типа BSTR: VariantInit(&rgInitProperties[1].vValue); Аналогичным образом заполняются элементы массива rgInitProperties, задающие имя пользователя и его пароль: rgInitProperties[2].dwPropertyID = DBPROP_AUTH_USERID; Свойство, задающее имя пользователя, имеет идентификатор DBPROP_AUTH_USERID, а свойство, определяющее пароль пользователя, — идентификатор DBPROP_AUTH_PASSWORD. Здесь для простоты мы опустили инициализацию полей dwOptions и colid. Она выполняется аналогично тому, как это делается для элементов массива, определяющих уровень приглашения и имя источника данных. На данном этапе мы подготовили массив rgInitProperties структур DBPROP, содержащий параметры для установки свойств объекта источника данных. Теперь нужно выполнить зададим свойства. Задание свойств выполняется методом SetProperties интерфейса IDBProperties. Этому методу передается указатель на структуру DBPROPSET, который, в свою очередь, используется для ссылки на только что подготовленный нами массив структур DBPROP. Структура DBPROPSET определена следующим образом: typedef struct
tagDBPROPSET Ее поля описаны в таблице 10-11. Таблица 10-11. Поля структуры DBPROPSET
Структура DBPROPSET создается и инициализируется очень просто: DBPROPSET rgInitPropSet; В поле guidPropertySet мы записали константу DBPROPSET_DBINIT, так как наш набор свойств отвечает за инициализацию источника данных. Массив rgInitProperties состоит из четырех элементов, поэтому в поле cProperties записывается значение 4. Что же касается указателя на массив, то мы помещаем его в поле rgProperties. Теперь у нас есть структура, описывающая массив свойств. Чтобы задать свойства, нам необходимо вызвать метод SetProperties интерфейса IDBProperties. А для этого, в свою очередь, нам потребуется указатель на интерфейс IDBProperties. Необходимый указатель мы получаем с помощью функции QueryInterface и записываем в переменную pIDBProperties типа IDBProperties*: IDBProperties* pIDBProperties; Через первый параметр мы передаем функции QueryInterface глобальный уникальный идентификатор интерфейса. В нашем случае идентификатором интерфейса IDBProperties служит значение константы IID_IDBProperties. Второй параметр служит для передачи указателя на переменную, в которую будет записан полученный указатель на интерфейс. Теперь мы можем устанавливать свойства: HRESULT hr; Метод SetProperties интерфейса IDBProperties имеет два параметра. Через второй параметр передается указатель на массив структур типа DBPROPSET, а через первый — количество таких структур в массиве. В нашем случае подготовлена одна структура DBPROPSET, описывающая массив DBPROP, поэтому значение первого параметра равно 1. Для наглядности мы показали на рис. 10-7 взаимосвязь структур DBPROPSET и DBPROP при установке свойств источника данных.
Рис. 10-7. Задание свойств источника данных Здесь мы подготовили массив из трех структур DBPROPSET, поэтому первый параметр метода SetProperties интерфейса IDBProperties имеет значение, равное 3. После того как программа установила свойства методом SetProperties, интерфейс IDBProperties станет нам не нужен. Поэтому мы освобождаем указатель на интерфейс методом Release: pIDBProperties->Release(); Последний этап в инициализации объекта провайдера источника данных — вызов метода Initialize интерфейса IDBInitialize: if(FAILED((pIDBInitialize)->Initialize())) Напомним, что указатель на этот интерфейс мы получили на этапе создания объекта провайдера источника данных функцией CoCreateInstance: hr = CoCreateInstance(CLSID_MSDASQL,
NULL, CLSCTX_INPROC_SERVER, В том случае, если значения свойств указаны правильно, инициализация пройдет успешно. Теперь можно переходить к созданию сеанса и выдаче команд. Для этого нам опять потребуется интерфейс IDBInitialize. Прежде чем выдавать команды, нам необходимо создать сеанс как объект Session. Этот объект обеспечивает методы для создания команд, наборов записей, для создания и изменения таблиц и индексов. Он также применяется для построения объектов транзакций, однако в этой книге мы этот случай не рассматриваем. Для создания объекта Session нужно получить указатель на интерфейс IDBCreateSession. Для этого применяют метод QueryInterface интерфейса IDBInitialize, вызвав его следующим образом: IDBCreateSession* pIDBCreateSession; В качестве первого параметра мы передаем методу QueryInterface идентификатор интерфейса IDBCreateSession в виде константы IID_IDBCreateSession. В случае успеха метод QueryInterface записывает указатель на интерфейс IDBCreateSession в переменную, расположенную по адресу, заданному вторым параметром. В нашем случае указатель на интерфейс IDBCreateSession будет храниться в переменной pIDBCreateSession типа IDBCreateSession*. С помощью интерфейса IDBCreateSession и метода CreateSession мы создаем сеанс: IDBCreateCommand* pIDBCreateCommand; Если новый сеанс создается в рамках агрегированного объекта, через первый параметр методу CreateSession передается указатель на управляющий интерфейс IUnknown. Если же сеанс не является составной частью агрегированного объекта (как в нашем случае), Вы можете указать здесь значение NULL. Второй параметр метода CreateSession предназначен для передачи идентификатора интерфейса. При создании сеанса мы получаем интерфейс, средствами которого можно создавать команды. Идентификатор этого интерфейса задается константой IID_IDBCreateCommand. И наконец, через третий параметр методу CreateSession передается адрес переменной, в которой будет сохранен указатель на интерфейс создания команд. После получения интерфейса создания команд IDBCreateCommand мы освободим ненужный нам более указатель на интерфейс IDBCreateSession с помощью метода Release: pIDBCreateSession->Release(); Выдача команд Для выдачи команд необходим объект Command. Он создается при помощи метода CreateCommand интерфейса IDBCreateCommand. Создание объекта Command Ниже показан фрагмент кода, создающего объект Command: ICommandText* pICommandText; Рассмотрим параметры использованного здесь метода CreateCommand. Первый параметр предназначен для передачи управляющего интерфейса IUnknown при агрегации. Мы не применяем агрегацию, поэтому указываем здесь значение NULL. Через второй параметр передается идентификатор интерфейса ICommandText, необходимого для определения команды. Третий параметр передает указатель на переменную, в которую будет записан указатель на только что упомянутый интерфейс ICommandText. После успешного получения указатель на интерфейс ICommandText мы можем освободить указатель на интерфейс IDBCreateCommand, который нам больше не потребуется: pIDBCreateCommand->Release(); Эта операция выполняется как обычно, при помощи метода Release. Для определения команды мы используем метод SetCommandText интерфейса ICommandText: LPCTSTR wSQLString = Первый параметр метода SetCommandText указывает синтаксис команды и общие правила, которые должен использовать провайдер источника данных в процессе разбора строки команды. Текст команды задается вторым параметром. Если первый параметр метода SetCommandText задан в виде константы DBGUID_SQL (как в нашем примере), то команда интерпретируется в соответствии с правилами языка SQL. В том случае, когда этот параметр задан как DBGUID_DEFAULT, интерпретация выполняется способом, заданным для провайдера источника данных по умолчанию. В частности, провайдер OLE DB может по умолчанию выполнять команды, не имеющие отношения к SQL. После определения команды можно отправить ее на выполнение при помощи метода Execute интерфейса ICommandText: LONG cRowsCounter; Первый параметр метода Execute используется для агрегирования. Мы задаем его в виде константы NULL. Второй параметр задает идентификатор интерфейса IRowset, необходимого для извлечения результата работы команды в виде набора записей. Метод Execute записывает указатель на интерфейс IRowset в переменную, адрес которой определен в последнем параметре. Третий параметр определяет указатель на структуру DBPARAMS, применяемую для запуска команд с параметрами. В этой книге мы не будем рассматривать такие команды. Если параметров нет, Вы можете задать здесь значение NULL. Через четвертый параметр методу Execute передается указатель на переменную, куда после выполнения команды записывается счетчик строк, на которые повлияла команда. Например, при создании набора записей в результате выполнения команды SELECT в эту переменную будет записано количество строк в образованном наборе записей. После выполнения команды мы должны освободить указатель на интерфейс ICommandText, вызвав метод Release: pICommandText->Release(); Как мы только что сказали, в результате выполнения команды методом Execute мы получаем указатель на интерфейс IRowset. Этот интерфейс используется для извлечения результатов выполнения команды, то есть для извлечения данных из полей строк набора записей, созданного командой. Помимо этого интерфейса, нам потребуются интерфейсы IColumnsInfo, IRowsetInfo, и IAccessor. Для извлечения данных из набора записей нам предстоит выполнить следующие процедуры: · получить описание столбов набора записей при помощи метода GetColumnInfo интерфейса IColumnsInfo; · выполнить привязку данных набора к переменным программы с помощью метода CreateAccessor интерфейса IAccessor; · извлечь идентификаторы строк набора методом GetNextRows интерфейса IRowset; · извлечь данные из полей строк методом GetData интерфейса IRowset. Рассмотрим поэтапное выполнение этих процедур. Получение описания набора записей На первом этапе обработки набора записей нам нужно получить описание столбцов набора, вызвав метод GetColumnInfo интерфейса IColumnsInfo. Для этого мы вначале получим указатель на интерфейс IColumnsInfo, воспользовавшись для этого указателем на интерфейс IRowset, ставший доступным после выполнения команды: IColumnsInfo* pIColumnsInfo; Указатель на интерфейс IColumnsInfo извлекается с помощью метода QueryInterface. Через первый параметр мы передаем этому методу идентификатор интерфейса IColumnsInfo в виде константы IID_IColumnsInfo, а через второй параметр — указатель на переменную, в которую будет записан указатель на интерфейс IColumnsInfo. Далее мы вызовем метод GetColumnInfo интерфейса IColumnsInfo: HRESULT hr; Методу GetColumnInfo через параметры передаются три указателя на переменные, в которые будет записана информация о столбцах набора записей. В переменную nColsCount, указатель на которую передается через первый параметр, метод GetColumnInfo запишет количество столбцов, имеющихся в наборе записей, или нулевое значение, если в результате выполнения команды набор записей не был создан. Через второй параметр методу GetColumnInfo передается адрес переменной, в которую будет записан адрес массива структур DBCOLUMNINFO, описывающих столбцы набора. И наконец, через третий параметр передается указатель на переменную, в которую будет записан указатель на память для всех строковых значений. Буфер может содержать одну или более строк, закрытых двоичным нулем. Структура DBCOLUMNINFO определена так: typedef struct tagDBCOLUMNINFO Поля этой структуры описаны в таблице 10-12. Таблица 10-12. Поля структуры DBPROPSET
После получения информации о столбцах набора мы должны освободить ненужный в дальнейшей работе указатель на интерфейс IColumnsInfo: pIColumnsInfo->Release(); Сведения, полученные на этом этапе, потребуются нам для выполнения привязки полей из строк набора записей к переменным, определенным в нашем приложении. Особый интерес вызывает информация, полученная в полях dwFlags (характеристики столбца) и wType (тип данных). Поле dwFlags может содержать константы, объединенные логической операцией ИЛИ (таблица 10-13). Таблица 10-13. Константы для заполнения поля dwFlags
Что же касается типа данных, указанного в поле wType, то в таблице 10-14 мы перечислили некоторые возможные значения для провайдера сервера Microsoft SQL Server. Таблица 10-14. Типы данных
Продолжим процесс извлечения значений из полей набора записей, образованного в результате выполнения команды. На данный момент мы извлекли характеристики столбцов набора данных и готовы выполнить привязку данных. Подготовка информации для привязки данных Для выполнения привязки данных мы должны создать массив структур DBBINDING, содержащий информацию о привязке для всех столбцов набора. Массив создается следующим образом: DBBINDING* pDBBind = NULL; Размер массива равен количеству строк в полученном наборе записей, которое мы определили на предыдущем этапе при помощи метода GetColumnInfo интерфейса IColumnsInfo. Определение структуры DBBINDING показано ниже: typedef struct tagDBBINDING Как видите, некоторые поля этой структуры называются также как и поля структуры DBCOLUMNINFO. Они имеют аналогичное назначение. Полное описание полей данной структуры Вы найдете в таблице 10-15. Таблица 10-15. Поля структуры DBCOLUMNINFO
Заполнение массива структур DBBINDING удобно выполнять в цикле. Перед запуском цикла нам нужно определить переменную nCurrentCol, в которой будет храниться номер текущего столбца, а также переменную cbRow для хранения текущего смещения поля в буфере строки: ULONG nCurrentCol; Чтобы обнулить неиспользуемые поля структуры DBBINDING, мы применяем функцию memset: memset(pDBBind, 0, sizeof(DBBINDING) * nColsCount); Цикл выглядит следующим образом: for(ULONG nCurrentCol = 0; nCurrentCol
< nColsCount; nCurrentCol++) На каждой итерации цикла помимо увеличения на единицу номера текущей строки nCurrentCol мы извлекаем длину данных текущего столбца из соответствующего элемента массива с информацией о наборе данных pColInfo. Эта информация записывается в поле cbMaxLen структуры pDBBind и используется для увеличения содержимого переменной cbRow, определяющей смещение данных текущего столбца в буфере. В теле этого цикла выполняется инициализация других полей массива структур привязки: pDBBind[nCurrentCol].iOrdinal = nCurrentCol + 1; В поле iOrdinal записывается номер текущего столбца, увеличенный на единицу. Это увеличение необходимо потому, что столбцы нумеруются, начиная с единицы, а начальное значение переменной цикла nCurrentCol равно нулю. В поле obValue записывается текущее смещение данных столбца в буфере потребителя данных, вычисляемое на каждой итерации цикла с учетом размера данных, хранящихся в столбце. Чтобы использовать поле obValue подобным образом, мы записали в поле dwPart константу DBPART_VALUE. Для того чтобы возложить задачу управления памятью на потребителя данных, мы записываем в поле dwMemOwner константу DBMEMOWNER_CLIENTOWNED. Так как наша привязка предназначена для работы с набором данных, а не для передачи параметров команде, в поле eParamIO необходимо записать значение DBPARAMIO_NOTPARAM. Инициализация полей bPrecision, bScale и wType массива pDBBind выполняется путем переписывания соответствующих значений из массива pColInfo, содержащего информацию о столбцах набора записей, полученного в результате выполнения команды. После подготовки массива с информацией о привязке мы должны выполнить привязку, создав объект Assessor. Для этого мы вначале получаем указатель на интерфейс IAccessor и сохраняем его в переменной pIAccessor: IAccessor* pIAccessor; Далее мы создаем массив структур DBBINDSTATUS, размер которого равен количеству столбцов в полученном наборе данных: DBBINDSTATUS* pDBBindStatus = NULL; Далее мы передаем количество столбцов в наборе данных, указатель на массив pDBBind с информацией о привязке данных, адрес переменной для хранения идентификатора привязки hAccessor и указатель методу CreateAccessor интерфейса IAccessor на массив структур DBBINDSTATUS: HACCESSOR hAccessor; Через первый параметр методу CreateAccessor передаются флажки свойств объекта привязки, которые определяют назначение этого объекта. Возможные значения флажков мы перечислены в таблице 10-16. Таблица 10-16. Поля структуры DBCOLUMNINFO
Третий параметр метода CreateAccessor задает количество байт в наборе параметров и не используется при работе с наборами записей. Поэтому для него указано нулевое значение. Массив структур DBBINDSTATUS, указатель на который передается методу CreateAccessor через последний параметр, позволяет отследить результат привязки для каждого столбца. Структура DBBINDSTATUS определена как двойное слово, в которое записываются флаги результата привязки: typedef DWORD DBBINDSTATUS; Эти флажки перечислены в таблице 10-17. Таблица 10-17. Поля структуры DBCOLUMNINFO
Теперь, когда привязка данных выполнена, мы можем приступить к извлечению данных из набора, созданного в результате выполнения команды. Эта операция выполняется в тройном вложенном цикле. Внешний цикл вызывает метод GetNextRows интерфейса IRowset, как это показано ниже: HROW rghRows[30]; Первый параметр метода GetNextRows определяет идентификатор оглавления набора записей и в нашем случае равен нулю. Второй параметр задает начальное смещение при обработке набора записей. Мы обрабатываем набор с самого начала и определяем для этого параметра нулевое значение. Через третий параметр мы передаем количество строк, извлекаемых для обработки из набора записей за один прием (мы задали произвольное значение, равное 30). Если указать для этого параметра отрицательное значение, выборка записей будет выполняться в обратном направлении (от конца набора записей к его началу). С помощью четвертого параметра мы предаем методу GetNextRows адрес переменной, в которую метод запишет количество строк, извлеченных из набора записей. И наконец, пятый параметр задает адрес массива для записи идентификаторов извлеченных строк. После обработки извлеченных строк мы освобождаем ресурсы, связанные с извлеченными строками, с помощью метода ReleaseRows. Обработка извлеченных строк выполняется в цикле второго уровня вложенности: char* pRowValues; Здесь мы получаем отдельные строки из блока строк, извлеченных только что рассмотренным методом GetNextRows, используя для этого массив идентификаторов строк rghRows и метод GetData. В качестве первого параметра методу GetData передается идентификатор извлекаемой строки. Второй параметр предназначен для передачи идентификатора объекта привязки. Данные строки записываются методом GetData в область памяти pRowValues, передаваемой методу GetData через третий параметр. Размер этой области хранится в переменной cbRow. Он был вычислен на этапе привязки данных. Теперь мы зададим обработку значений отдельных полей текущей записи, извлеченной из набора. Она выполняется в цикле третьего уровня вложенности: ULONG nCurrentCol; В этом цикле мы можем ссылаться как на массив pColInfo, содержащий полную информацию о столбцах (имя столбца, тип данных и т. д.), а также на массив значений pRowValues. По завершении обработки набора записей Ваша программа должна освободить объект привязки и указатель на интерфейс IAccessor: pIAccessor->ReleaseAccessor(hAccessor,
NULL); Первая операция выполняется с помощью метода ReleaseAccessor, а вторая — методом Release. Исходный текст программы OLEDB В качестве примера программы, написанной на языке C++ и обращающейся к базе данных средствами OLE DB, приведем исходные тексты простой утилиты OLEDB, отображающей на консольном экране информацию из таблицы посетителей clients нашего Интернет-магазина. Программа получает из базы данных и выводит на экран идентификатор записи покупателя, его имя, пароль, дату регистрации и электронный почтовый адрес E-Mail: 1 frolov 123 01.12.1999 20:23:42
frolov@glasnet.ru Полные исходные тексты утилиты OLEDB вы найдете в листинге 10-5. Листинг 10-5 Вы найдете в файле chap10\oledb\oledb.cpp на прилагаемом к книге компакт-диске. Рассмотрим эти исходные тексты в деталях. В самом начале файла исходных текстов oledb.cpp мы определили несколько макросов и включили некоторые include-файлы. Для того чтобы все строки и символы представлялись в кодировке UNICODE, мы ввели следующие определения: #define UNICODE Инициализация констант OLE DB выполняется при помощи определения макроса DBINITCONSTANTS: #define DBINITCONSTANTS И наконец, для работы с глобальными уникальными идентификаторами в приложении определен макрос INITGUID: #define INITGUID Помимо обычных для консольных приложений Windows файлов windows.h и stdio.h, мы включили в исходный текст файлы oledb.h, oledberr.h, msdaguid.h и msdasql.h: #include <oledb.h> Файлы oledb.h и oledberr.h предназначены для определений объектов и интерфейсов OLE DB, а файлы msdaguid.h и msdasql.h относятся к провайдеру ODBC, использованному нами для создания источника данных. Для инициализации системы COM перед началом работы программы и для освобождения ресурсов COM перед завершением программы мы определили в области глобальных переменных уже знакомую Вам по предыдущей главе переменную com_init класса ComInit: struct ComInit До начала работы выполняется инициализация COM методом CoInitialize, а до ее завершения — освобождение ресурсов COM методом CoUninitialize, В области глобальных переменных мы также определили три указателя на интерфейсы IMalloc, IDBInitialize и IRowset: IMalloc* pIMalloc = NULL; Первый из них используется для управления памятью, второй — для инициализации объекта провайдера источника данных, а третий — для работы с извлеченным набором записей. Исходный текст этой функции, получающей управление при запуске программы, представлен ниже: int main(int argc, TCHAR* argv[],
TCHAR* envp[]) В начале своей работы функция main выполняет инициализацию источника данных, вызывая для этого функцию init, определенную в нашей программе. Если инициализация выполнилась успешно, функция main запускает команду, извлекающую из таблицы clients информацию о покупателях. В том случае, если команда выполнена без ошибок, вызывается функция get_records, извлекающая или отображающая в консольном окне строки таблицы clients. При возникновении каких-либо ошибок в работе программы функция main освобождает указатели на интерфейсы IMalloc, IDBInitialize и IRowset. Предварительно она убеждается в том, что указатели не содержат нулевые значения. Перед освобождением указателя на интерфейс IDBInitialize мы вызываем метод Uninitialize, освобождающий ресурсы, полученные программой при инициализации источника данных. Перед тем как приступить к инициализации источника данных, функция init получает память для системы COM, вызывая для этого функцию CoGetMalloc: if(FAILED(CoGetMalloc(MEMCTX_TASK,
&pIMalloc))) В результате в глобальную переменную pIMalloc записывается указатель на интерфейс системы управления памятью COM. Приложение может использовать этот указатель для вызова методов интерфейса IMalloc, таких, как Alloc, Realloc, Free и т. д. Память, полученная таким образом, применяется в многопоточной среде. Наша программа заказывает память неявно, обращаясь к интерфейсам OLE DB, однако, прежде чем завершить работу, функция get_records вызывает метод Free интерфейса IMalloc для освобождения памяти, заказанной для описания столбцов набора записей. Дальнейшие действия, выполняемые функцией init, мы подробно описали в начале этой главы. Вначале функция создает объект IDBInitialize и получает указатель на соответствующий интерфейс: CoCreateInstance(CLSID_MSDASQL, NULL,
CLSCTX_INPROC_SERVER, Далее функция init готовит массив свойств rgInitProperties и, пользуясь указателем на интерфейс IDBInitialize, выполняет инициализацию источника данных: VariantInit(&rgInitProperties[0].vValue); Здесь мы привели только фрагмент кода, выполняющий установку свойств, необходимых для инициализации. Обратите внимание, что перед вызовом метода инициализации наша программа освобождает память, заказанную для переменных типа BSTR: SysFreeString(rgInitProperties[1].vValue.bstrVal); После установки значений свойств эти переменные уже не нужны. Функция startCommand предназначена для создания сеанса, а также создания и запуска команды. Так как мы уже достаточно подробно описали этот процесс, то не будем повторяться. Отметим только, что данная функция запускает команду SELECT, выбирающую из таблицы покупателей clients поля с именами ClientID, UserID, Password, RegisterDate и Email: LPCTSTR wSQLString = OLESTR("SELECT ClientID, UserID, Password, RegisterDate, Email FROM clients"); Методику, использованную нами в этой функции для извлечения и обработки записей набора, полученного в результате выполнения команды SELECT, мы описали очень подробно. Здесь же мы остановимся только на процессе получения данных из полей текущей записи и на выполнении преобразования типов для вывода на консоль. Обработка полей текущей строки выполняется в цикле: for(nCurrentCol = 0; nCurrentCol <
nColsCount; nCurrentCol++) Программа выводит на консоль данные в текстовом виде, однако извлекаемые данные могут иметь различный тип в зависимости от столбца. Прежде чем выполнять преобразование, мы определяем тип данных в текущем столбце, анализируя соответствующий элемент массива описания столбцов pColInfo. Тип данных записан в поле wType. Для разработки кода, выполняющего преобразование, Вам помогут данные из таблицы 5-8. Анализируя содержимое поля wType, Вы сможете выбрать подходящий способ преобразования. Для столбцов таблицы, содержащих текстовые значения, тип данных будет DBTYPE_STR. В этом случае наша программа передает функции printf, выполняющей преобразование данных и вывод результата на консоль, указатель на данные. Если же столбец таблицы содержит числовое значение DBTYPE_I4, мы используем в функции printf другой спецификатор формата и передаем данные не через указатель, а непосредственно. Сложнее дело обстоит с данными типа DBTYPE_DBTIMESTAMP, содержащими отметку о времени. Для того чтобы получить отдельные составляющие такой отметки, мы определили в своей программе указатель ts типа DBTIMESTAMP. Далее мы записываем в него значение адреса поля данных с временной отметкой и обращаемся к полям структуры DBTIMESTAMP для отображения даты регистрации посетителя в форматированном виде. Прежде чем завершить работу, функция get_records удаляет заказанные массивы и освобождает память, полученную для буферов: delete [] pDBBind; Использование библиотеки шаблонов ATL Как показано в примере из предыдущего раздела, прямое использование объектного интерфейса OLE DB заставляет разработчика вникать во множество деталей, имеющих отношение к технологии применения модели компонентного объекта COM. Например, Вам придется явным образом получать указатели на интерфейсы, а потом заботиться об их освобождении, проверять коды завершения методов и функций, создавать сложные взаимосвязанные структуры для привязки данных и т. д. Однако те из Вас, кто пользуется для создания приложений системой программирования Microsoft Visual C++ версии 6.0 или более новой, получают возможность заметно сократить объем кода, не имеющего непосредственного отношения к выполнению операций с базой данных, а значит, сконцентрироваться на решении своей прикладной задачи. Такую возможность предоставляет библиотека шаблонов ActiveX Template Library (ATL). Она существенно упрощает как создание новых элементов управления ActiveX, так и использование готовых элементов управления ActiveX, к которым можно отнести объекты OLE DB. Шаблоны этой библиотеки обеспечивают простой доступ к возможностям OLE DB, упрощают процесс привязки данных наборов записей и параметров процедур, а также допускают использование естественных типов данных, привычных для разработчиков программ C++. Классы для работы с источником данных OLE DB Создавая приложения OLE DB с использованием библиотеки шаблонов ATL, Вы должны применять для работы с источником данных специальный набор классов. Его мы рассмотрим в этом разделе. Эти классы скрывают внутреннюю сложность обращения к объектам OLE DB, предоставляя в распоряжение программистов относительно простой набор методов и свойств. Для использования этих классов в исходные тексты Вашего приложения необходимо включить оператором #include файл atldbcli.h: #include <atldbcli.h> Этот класс инкапсулирует в себе соединение с объектом источника данных OLE DB. В рамках этого соединения приложение может создавать один или несколько сеансов. С применением класса CDataSource инициализация источника данных выполняется так же легко, как и в серверных сценариях, обращающихся к объектам ADO: CDataSource dsDSN; Все, что Вам нужно сделать для создания соединения, — вызвать метод Open класса CDataSource. В данном классе имеется несколько перегруженных определений метода Open, позволяющих указывать все или только некоторые параметры. В нашем случае через первый параметр мы передаем методу Open идентификатор провайдера данных в виде текстовой строки. Другие перегруженные определения этого метода позволяют ссылаться на глобальный уникальный идентификатор провайдера CLSID. Через второй, третий и четвертый параметры методу Open передаются имя источника данных, имя пользователя и пароль пользователя соответственно. При необходимости Вы сможете передать эти параметры и через структуру DBPROPSET, применяя другой вариант определения метода Open. Когда работа с источником данных закончена, его нужно закрыть, вызвав метод Close класса CDataSource: dsDSN.Close(); В классе CDataSource определено еще несколько методов, которые мы не используем в нашей книге. К ним относятся методы GetProperties и GetProperty, предназначенные для определения свойств соединения с провайдером, метод GetInitializationString, позволяющий получить строку инициализации источника данных (включая пароль) и другие методы, предназначенные для соединения с источником данных. Для создания сеанса, необходимого для работы с командами и наборами записей, Вы должны использовать класс CSession. Это очень просто: CSession sSession; Вам необходимо вызвать метод Open класса CSession, передав ему в качестве параметра ссылку на предварительно открытый объект класса CDataSource. По завершении работы с источником данных приложение должно закрыть все открытые сеансы методом Close, как это показано ниже: sSession.Close(); Помимо методов Open и Close, в классе CSession определено несколько методов для работы с транзакциями. Это StartTransaction (начало транзакции), Commit (фиксация транзакции), Abort (отмена транзакции) и GetTransactionInfo (получение информации о транзакции). Класс CСommand обеспечивает методы для выполнения команд. Он определен следующим образом: template <class TAccessor =
CNoAccessor, class TRowset = CRowset, class TMultiple = CNoMultipleResults> Здесь класс TAccessor представляет собой класс объекта привязки Accessor, с которым мы уже имели дело в этой главе, TRowset — класс набора записей, создаваемого при выполнении команды, и Tmultiple, который используется с командами, возвращающими одновременно несколько результатов. Несмотря на устрашающий вид определения класса CСommand, пользоваться им достаточно просто. Вот как мы создаем объект cmd этого класса: CCommand <CAccessor<tabClients> > cmd; Здесь мы ссылаемся на класс tabClients, определенный в нашем приложении для выполнения привязки данных: class tabClients Этот класс определяет всю информацию, необходимую для выполнения привязки. Фактически он содержит описание полей набора данных, который будет образован после выполнения запроса к базе данных. В нашем случае это таблица clients, входящая в состав базы данных Интернет-магазина, о которой мы уже рассказывали ранее (поэтому, кстати, мы и выбрали для класса привязки имя tabClients). Заметьте, мы не создаем объектов класса tabClients, нам нужно только его определение. В классе tabClients мы расположили определения полей, сделанные с применением обычных типов данных C++. Кроме этого, в этом классе есть описание столбцов набора записей, сделанное при помощи макрокоманд BEGIN_COLUMN_MAP, COLUMN_ENTRY и END_COLUMN_MAP. Через единственный параметр макрокоманде BEGIN_COLUMN_MAP нужно указать имя класса привязки. В нашем случае это tabClients. Макрокоманда COLUMN_ENTRY, предназначенная для выполнения привязки данных, имеет два параметра — номер столбца и имя поля данных записи. И наконец, макрокоманда END_COLUMN_MAP, закрывающая определение столбцов набора, не имеет параметров. Для того чтобы запустить команду на выполнение, Вы должны воспользоваться методом Open, определенным в классе CCommand: TCHAR mySQL[] = Этот метод очень прост в применении. Достаточно передать ему в качестве первого параметра ссылку на открытый сеанс, а в качестве второго — адрес текстовой строки команды, подлежащей выполнению. В результате выполнения команды создается набор записей, доступ к которому осуществляется с помощью все того же класса CCommand. Для этого в программе необходимо организовать цикл: while(cmd.MoveNext() == S_OK) Здесь мы перебираем записи образованного набора с помощью метода MoveNext, определенного в классе CCommand. Для доступа к значениям полей достаточно просто сослаться на соответствующие поля класса CCommand. Это возможно благодаря применению библиотеки шаблонов ATL. По завершении цикла обработки записей приложение должно закрыть объект класса CCommand, сеанс и соединение с источником данных. Все это делается методами Close соответствующих классов: cmd.Close(); Исходный текст программы ATLOLEDB Для демонстрации простоты использования объектного интерфейса OLE DB с применением библиотеки шаблонов ATL мы подготовили консольную программу ATLOLEDB. Она решает ту же задачу, что и предыдущая, рассмотренная в этой главе — отображает содержимое нескольких полей таблицы регистрации посетителей Интернет-магазина clients. Полный исходный текст программы ATLOLEDB Вы найдете в листинге 10-6. Листинг 10-6 Вы найдете в файле chap10\atloledb\atloledb.cpp на прилагаемом к книге компакт-диске. Для того чтобы использовать шаблоны ATL, предназначенные для работы с объектами OLE DB, мы включили в исходный текст нашего приложения файл atldbcli.h: #include <atldbcli.h> Так как наша программа выводит результаты на консоль и при этом пользуется манипуляторами ввода/вывода, мы включили файлы iostream и iomanip: #include <iostream> Кроме того, для применения ATL необходимо подключить пространство имен std: using namespace std; В области глобальных определений мы расположили определение класса привязки переменных к набору записей tabClients: class tabClients О назначении и внутреннем устройстве этого класса мы рассказывали ранее Помимо этого, в области глобальных определений мы разместили три объекта классов CDataSource, CSession и CCommand: CDataSource dsDSN; Объект dsDSN используется для создания соединения с источником данных, объект sSession нужен для образования сеанса, а объект cmd — для выдачи команды и обработки результата ее выполнения. Наша программа настолько проста, что все свои действия она выполняет в рамках единственной функции main. В начале своей работы программа выполняет инициализацию COM, вызывая для этого функцию CoInitialize: CoInitialize(NULL); Заметим, что освобождение ресурсов выполняется автоматически, поэтому при использовании шаблонов ATL функцию CoUninitialize вызывать не надо (и нельзя). После инициализации наша программа открывает источник данных и сеанс: HRESULT hr; В случае возникновения ошибок программа завершает свою работу с кодом возврата 1. Далее программа выполняет команду: TCHAR mySQL[] = "SELECT ClientID,
UserID, Password, RegisterDate, Email FROM clients"; В качестве команды мы используем строку SQL, выполняющую запрос к таблице покупателей clients. Записи набора, образованного в результате выполнения этой команды, обрабатываются в цикле: while(cmd.MoveNext() == S_OK) Здесь мы просто выводим извлеченные значения в выходной поток cout, выполняя форматирование манипуляторами ввода/вывода (установку ширины колонки и выравнивание). Что же касается форматирования поля даты регистрации, то здесь мы использовали уже знакомый Вам трюк, связанный с использованием структуры DBTIMESTAMP. Создав переменную ts типа DBTIMESTAMP, мы записали в нее значение, полученное из поля cmd.m_RegisterDate. Далее мы выполняем преобразование формата, обращаясь к полям переменной ts. Перед завершением своей работы программа закрывает объект команды, сеанс и соединение с источником данных: cmd.Close(); Связь приложений с базами данных через ODBC Последний метод доступа, о котором мы расскажем в этой главе, это Microsoft Open Database Connectivity (ODBC). Интерфейс ODBC представляет собой набор предназначенных для доступа к базам данных функций программного интерфейса. Этот набор предполагает использование структурного языка запросов SQL. Для того чтобы интерфейс ODBC стал доступен программам, необходимо установить драйвер ODBC. Такой драйвер имеется в составе Microsoft SQL Server, а также в составе многих других СУБД, рассчитанных на работу в среде операционных систем Microsoft Windows, Macintosh и некоторых версий Unix. При создании приложений с базами данных для Интернета интерфейс ODBC пригодится Вам для связи расширений сервера Web (таких, как программы CGI и приложения ISAPI) с базами данных. При этом вызов функций ODBC будет выполняться как непосредственно из программ расширений, так и через дочерние процессы, запускаемые расширениями для обращения к базам данных (это иногда требуется для повышения устойчивости сервера Web к программным ошибкам, допущенным при обращении к базе данных). Заметим, что в отличие от ADO, интерфейс ODBC не является объектным. Поэтому он недоступен из серверных сценариев JScript и VB Script, расположенных в страницах ASP. В нашей книге мы не будем описывать все возможности ODBC — речь пойдет только о самых необходимых. Мы, в частности, расскажем о том, как посредством этого интерфейса программы могут выполнять предложения языка SQL и запускать хранимые процедуры с входными и выходными параметрами. Именно эти операции чаще всего нужны при создании реальных приложений. В этом разделе речь пойдет о назначении и параметрах основных функций программного интерфейса ODBC. Помимо этих функций, обеспечивающих прямой доступ к ODBC, корпорация Microsoft разработала ряд программных интерфейсов и классов, предназначенных для обращения к ODBC. Это такие интерфейсы, как RDO и DAO, а также классы MFC и DAO. Интерфейсы RDO и DAO предназначены главным образом для создания приложений Visual Basic, а классы MFC и DAO — для создания приложений на основе Microsoft Visual C++, к тому же имеющих интерактивный интерфейс пользователя. При разработке приложений Интернет для интерактивной части проекта обычно применяется технология ASP, серверные сценарии и ADO, о чем мы подробно рассказывали в первых главах нашей книги. Что же касается расширений сервера Web, то они не имеют никакого непосредственного интерфейса пользователя. Поэтому классы MFC и DAO, ориентированные на автоматизированное создание диалоговых приложений средствами мастеров Microsoft Visual C++, не окажут Вам заметной помощи. Именно поэтому мы расскажем Вам только о непосредственном интерфейсе ODBC. Программа, обращающаяся к базам данных посредством интерфейса ODBC, обычно выполняет следующие действия: · инициализирует среду выполнения; · подключается к источнику данных; · создает и выполняет команды; · обрабатывает результат выполнения команды; · освобождает ресурсы, полученные для работы с ODBC. Если команда предназначена для выполнения хранимой процедуры, приложение должно выполнить привязку входных и выходных параметров этой процедуры (а также при необходимости и кода завершения процедуры) к локальным переменным, определенным внутри тела программы. Обработка результата также связана с привязкой данных к локальным переменным. Вы уже знакомы с этой процедурой из предыдущей главы, посвященной интерфейсу OLE DB. Хотя приложения ODBC выполняют эту операцию по-другому, смысл ее не меняется — устанавливается соответствие между локальными переменными и полями набора записей, полученных при выполнении команды SQL. Нетрудно заметить, что ранее мы говорили о тех же самых действиях, что применяются для работы с базами данных, но выполняемых посредством методов доступа ADO и OLE DB. Действительно, набор действий остается тем же самым. Меняется только способ их реализации. Рассмотрим назначение функций ODBC, вызываемых на различных этапах работы приложения ODBC. Для выполнения инициализации среды выполнения приложение ODBC использует такие функции, как SQLAllocHandle и SQLSetEnvAttr. Первая из них отвечает за собственно инициализацию, а вторая позволяет устанавливать параметры среды исполнения. Вот прототип функции SQLAllocHandle: SQLRETURN SQLAllocHandle(SQLSMALLINT
hType, В качестве первого параметра hType функции SQLAllocHandle передается тип идентификатора. Это может быть идентификатор среды SQL_HANDLE_ENV, идентификатор соединения с источником данных SQL_HANDLE_DBC, идентификатор строки SQL_HANDLE_STMT или дескриптора SQL_HANDLE_DESC. Второй параметр inpHandle определяет, в каком контексте нужно получить идентификатор. Здесь могут быть указаны константы SQL_NULL_HANDLE, SQL_HANDLE_ENV или SQL_HANDLE_DBC. И наконец, третий параметр определяет адрес переменной, в которую записывается идентификатор, полученный функцией SQLAllocHandle. При успешном завершении функция SQLAllocHandle возвращает значения SQL_SUCCESS или SQL_SUCCESS_WITH_INFO. Первая из этих констант возвращается, если операция завершилась успешно. Вторая константа также означает успешное завершение и, кроме того, сообщает дополнительную информацию. В том случае, если функция SQLAllocHandle завершилась с ошибкой, возвращается значение SQL_INVALID_HANDLE или SQL_ERROR. Перечисленные выше константы возвращаются многими функциями программного интерфейса ODBC. Немного позже мы расскажем о том, как программы обрабатывают ошибочные ситуации, извлекая коды ошибок и тексты сообщений об ошибках. Перед завершением своей работы приложение должно освободить идентификаторы, полученные при вызове функции SQLAllocHandle. Для этого предназначена функция SQLFreeHandle. Она имеет два параметра: SQLRETURN SQLFreeHandle (SQLSMALLINT hType, SQLHANDLE hHandle); Через первый параметр функции SQLFreeHandle передается тип идентификатора (такой же, как и функции SQLAllocHandle), а через второй — освобождаемый идентификатор. Инициализация среды выполнения Рассмотрим фрагмент кода приложения, выполняющий инициализацию среды для выполнения запроса к базе данных. Прежде всего программа должна получить идентификатор среды типа SQL_HANDLE_ENV: SQLHENV hEnv = SQL_NULL_HENV; Он записывается в переменную hEnv. На следующем этапе нам нужно установить атрибуты среды, в частности указать номер версии ODBC, равный 3. В результате приложение сможет воспользоваться особенностями этой версии драйвера. Так, драйвер ODBC будет работать с новыми кодами даты и времени SQL_TYPE_DATE, SQL_TYPE_TIME, SQL_TYPE_TIMESTAMP, SQL_C_TYPE_DATE, SQL_C_TYPE_TIME, SQL_C_TYPE_TIMESTAMP, а также — возвращать коды SQLSTATE при обработке ошибок. Атрибуты среды устанавливаются с помощью функции SQLSetEnvAttr, имеющей четыре параметра: rc = SQLSetEnvAttr(hEnv, SQL_ATTR_ODBC_VERSION,
Через первый параметр этой функции передается идентификатор среды, для которой выполняется настройка атрибутов. Второй параметр задает атрибут, подлежащий редактированию. В частности, значение SQL_ATTR_ODBC_VERSION используется при настройке версии драйвера ODBC. Третий параметр функции SQLSetEnvAttr задает значение атрибута (для численных значений) или адрес строки атрибута (для атрибутов, заданных в виде текстовой строки). Смысл четвертого параметра зависит от типа значения атрибута, передаваемого через третий параметр. Если значение числовое (как в нашем случае), четвертый параметр определяет тип значения атрибута, а если строчное — длину строки. Инициализация среды для установки соединения На втором этапе инициализации Вам надо получить идентификатор соединения типа SQL_HANDLE_DBC, который создается в контексте только что созданного идентификатора среды SQL_HANDLE_ENV: SQLHDBC hDbc = SQL_NULL_HDBC; Обратите внимание, что мы передаем функции SQLAllocHandle через второй параметр идентификатор hEnv, имеющий тип SQL_HANDLE_ENV. Теперь, после выполнения второго этапа инициализации, у нас уже есть два идентификатора — hEnv (идентификатор среды выполнения) и hDbc (идентификатор среды соединения). Для установки соединения с источником данных Вам придется воспользоваться функцией SQLConnect, прототип которой приведен ниже: SQLRETURN SQLConnect(SQLHDBC
hConnection, Через первый параметр hConnection функции SQLConnect передается идентификатор соединения типа SQL_HANDLE_DBC, полученный на втором этапе инициализации. Второй параметр ServerName определяет имя сервера, заданное в виде текстовой строки, а третий (с названием ServerNameLength) — длину этой строки. Аналогично параметры UserName и Password задают имя пользователя и его пароль, а параметры UserNameLength и PasswLength — размер строк имени пользователя и пароля. Вот фрагмент текста программы, выполняющий соединение с источником данных BookStore: UCHAR szDSN[SQL_MAX_DSN_LENGTH + 1] =
"BookStore"; В случае успешного соединения функция SQLConnect вернет значение SQL_SUCCESS или SQL_SUCCESS_WITH_INFO, а при ошибке — значение SQL_INVALID_HANDLE или SQL_ERROR. Программный интерфейс ODBC предоставляет несколько возможностей для выполнения команд, здесь, однако, мы рассмотрим только один, связанный с использованием функции SQLExecDirect. Выполнение команды с применением этой функции состоит из двух этапов. На первом нужно создать идентификатор команды типа SQL_HANDLE_STMT, а на втором — выполнить команду, вызвав функцию SQLExecDirect. Получение идентификатора команды Получение идентификатора команды реализуется обычным способом с применением функции SQLAllocHandle: SQLHSTMT hStmt = SQL_NULL_HSTMT; Обратите внимание на то, что идентификатор команды создается в контексте идентификатора соединения типа SQL_HANDLE_DBC, поэтому через второй параметр мы передаем функции SQLAllocHandle значение hDbc. Идентификатор соединения hDbc был получен на предыдущем этапе инициализации. Для запуска команды на выполнение надо вызвать функцию SQLExecDirect, прототип которой расположен ниже: SQLRETURN SQLExecDirect(SQLHSTMT
hStatement, Через первый параметр этой функции передается идентификатор команды типа SQL_HANDLE_STMT, через второй — строка команды, а через третий — длина строки команды. Если команда выполнена без ошибок, функция SQLExecDirect возвращает значение SQL_SUCCESS или SQL_SUCCESS_WITH_INFO, а при ошибке — значение SQL_INVALID_HANDLE или SQL_ERROR. Возможно также, что Вы получите коды возврата SQL_NEED_DATA, SQL_STILL_EXECUTING и SQL_NO_DATA. Значение SQL_NEED_DATA возвращается при использовании так называемых параметров времени исполнения (data-at-execution parameter). Такой тип параметров предполагает использование для передачи данных функций SQLParamData и SQLPutData. Мы в своих программах не будем применять параметры времени исполнения. Значение SQL_NO_DATA возвращается при выполнении команд, не вызывающих создания выходных наборов записей. Км ним относятся, например, команды удаления или обновления строк. Ниже показан пример вызова команды, выполняющей выборку полей ManagerID, Name, Password, LastLogin и Rights из таблицы managers: rc = SQLExecDirect(hStmt, (unsigned
char*) В качестве длины строки, передаваемой функции SQLExecDirect через последний параметр, мы указали константу SQL_NTS. Эта константа означает, что длина строки определяется закрывающим ее двоичным нулем. Таким образом, нам не надо определять длину строки команды явным образом при помощи такой функции, как strlen. Обработка результата выполнения команды Если в результате выполнения команды создан набор записей, программа может его получить посредством соответствующих функций интерфейса ODBC. Однако перед тем как это сделать, она должна выполнить привязку полей набора записей к локальным переменным, определенным внутри программы. Привязка полей к локальным переменным Такая операция выполняется функцией SQLBindCol: SQLRETURN SQLBindCol(SQLHSTMT
hStatement, Параметр hStatement задает идентификатор команды, для которой выполняется привязка. Это как раз тот идентификатор, с использованием которого функция SQLExecDirect выполняла команду. Через параметр NumberOfColumn необходимо передать номер столбца набора данных, созданного в результате выполнения команды. Если в наборе нет столбца bookmark, то нумерация выполняется, начиная с единицы, а если есть — то с нуля. Параметры VariableType и VariableValuePtr, задают соответственно тип локальной переменной, для которой выполняется привязка, и адрес этой локальной переменной. С помощью параметра BufferSize необходимо указать размер области памяти, отведенной для локальной переменной с адресом VariableValuePtr (с учетом двоичного нуля, закрывающего текстовую строку). Это значение используется драйвером ODBC в качестве ограничителя, для того чтобы избежать записи данных за пределами буфера. Такая ситуация иногда возникает при извлечении из базы данных содержимого полей переменной длины. Значение параметра BufferSize игнорируется при записи данных в переменные фиксированной длины типа целых чисел. Параметр cbSize бывает как входным, так и выходным. Он задает адрес переменной, в которую записывается размер данных, прочитанных функцией извлечения записей SQLFetch (или SQLFetchScroll). Функция SQLBulkOperations использует этот параметр как входной. В качестве примера приведем фрагмент кода, выполняющего привязку одного числового поля, одного текстового поля и одного поля, содержащего отметку о времени: Локальные переменные, которые будут привязаны к полям, определены так: SQLINTEGER nManagerID; Мы выполним привязку к полям таблицы managers с именами ManagerID, Name и LastLogin. Вот фрагмент кода для первого из них: SQLINTEGER cbManagerID; Здесь выполняется привязка первого столбца, поэтому мы передаем функции SQLBindCol через второй параметр значение 1. Константа SQL_C_SLONG задает тип данных, соответствующий стандартному типу C «long int». Константы для других типов Вы найдете в таблице 6-1. Хотя мы и указали в пятом параметре размер области памяти, выделенной для переменной nManagerID, он будет проигнорирован, так как тип SQL_C_SLONG занимает область памяти фиксированного размера. Привязка переменной szName, в которую будет записана текстовая строка, выполняется аналогично: SQLINTEGER cbName; Здесь мы указали тип данных SQL_C_CHAR, соответствующий типу данных C «unsigned char*». Константа MAXNAME ограничивает длину буфера, не позволяя драйверу ODBC выйти за его границы в процессе записи данных из поля Name. Для привязки поля LastLogin (содержащего отметку о дате и времени последнего подключения), мы указали тип данных SQL_C_TYPE_TIMESTAMP: SQLINTEGER cbLastLogin; Значение, заданное нами в пятом параметре, будет проигнорировано. Мы указали его только для общности. В таблице 10-18 мы перечислили идентификаторы типов, передаваемых функции SQLBindCol, для разных типов данных. Там же Вы найдете и типы данных ODBC, которые потребуются при вызове хранимых процедур SQL Server. Таблица 10-18. Идентификаторы типов данных C и ODBC
В таблице есть ссылки на типы данных DATE_STRUCT, TIME_STRUCT, TIMESTAMP_STRUCT, SQL_NUMERIC_STRUCT и SQLGUID. Эти структуры предназначены для представления даты, времени, отметки о времени, числовых значений и глобальных уникальных идентификаторов GUID. Для удобства ниже мы приводим их определения: struct tagDATE_STRUCT После того как Ваше приложение выполнило привязку данных, оно может приступать к извлечению записей из набора, созданного в результате выполнения команды. Эта операция выполняется в простом цикле, показанном ниже: while((rc = SQLFetch(hStmt)) !=
SQL_NO_DATA) Здесь для извлечения очередной записи набора мы использовали функцию SQLFetch. В качестве единственного параметра этой функции передается идентификатор команды. Когда все записи набора будут получены, функция SQLFetch вернет значение SQL_NO_DATA. Это ее свойство мы использовали для завершения цикла. Вы также можете усовершенствовать цикл, прерывая его работу в случае возникновения ошибок. Внутри цикла программа непосредственно обращается к переменным, для которых выполняется привязка, с целью извлечения значений. Как мы уже говорили, в случае возникновения ошибок функции ODBC возвращают значения, такие, как SQL_INVALID_HANDLE или SQL_ERROR. Однако в большинстве случаев такой информации недостаточно. Для того чтобы получить развернутое описание ошибки, необходимо запросить у драйвера ODBC диагностические записи. Эта операция выполняется с применением функции SQLGetDiagRec. Отдельные поля диагностических записей извлекаются при помощи функции SQLGetDiagField. Извлечение диагностических записей Логика обработки ошибок, рекомендуемая в руководстве Microsoft, предполагает, что функции получения диагностических записей вызываются всякий раз, когда функции ODBC возвращают значения, отличные от SQL_SUCCESS. Однако в некоторых случаях Вы можете проигнорировать дополнительные информационные сообщения, возникающие при коде возврата SQL_SUCCESS_WITH_INFO, не рассматривая данную ситуацию как ошибочную. Так как с одной ошибочной ситуацией иногда связано несколько диагностических записей, функция SQLGetDiagRec должна извлекать эти записи в цикле. Рассмотрим прототип функции SQLGetDiagRec: SQLRETURN SQLGetDiagRec( Через параметр hType Вы передаете тип идентификатора, для которого нужно получить диагностику. Здесь Вы можете указать хорошо знакомые значения SQL_HANDLE_ENV, SQL_HANDLE_DBC, SQL_HANDLE_STMT и SQL_HANDLE_DESC. Например, если ошибка возникла при выполнении команды, первый параметр должен содержать тип идентификатора команды SQL_HANDLE_STMT, если при создании соединения с источником данных — тип SQL_HANDLE_DBC, и т. д. Параметр hHandle используется для передачи самого идентификатора. Через параметр nRecord Вы должны передать номер извлекаемой записи. Обычно значение этого параметра последовательно, начиная с единицы, увеличивается в цикле. Параметр SQLState должен содержать указатель на буфер, в который записывается код состояния SQLSTATE. Первые два символа в этом буфере указывают класс состояния, а следующие три — подкласс. Подробную информацию о кодах состояния Вы найдете в документации на Microsoft SQL Server. Через параметр pNativeErrorPtr необходимо передать указатель на буфер, в котором будет храниться естественный код ошибки, зависящий от источника данных. Текст сообщения об ошибке записывается в буфер, адрес которого передается функции SQLGetDiagRec через параметр pMessageText. Размер этого буфера должен быть указан с помощью параметра cbBuffer. И наконец, последний параметр pcbText используется для передачи указателя на переменную, в которую будет записана длина упомянутого выше сообщения об ошибке. Вот как, например, выглядеть цикл извлечения диагностических записей: RETCODE rc = SQL_SUCCESS; Указанным выше методом можно получить первый из двух типов диагностических записей, а именно записи заголовка. Они создаются при возникновении любых ошибок, кроме тех, что вызывают появление кода завершения SQL_INVALID_HANDLE. При использовании драйверов ODBC версии 3.x становятся доступными диагностические записи второго типа, называемые записями состояния. Они генерируются отдельно для каждой записи заголовка и могут быть получены посредством функции SQLGetDiagField: SQLRETURN SQLGetDiagField( Через первый параметр hType Вы должны передать функции SQLGetDiagField тип идентификатора, для которого нужно получить диагностику. Это константы SQL_HANDLE_ENV, SQL_HANDLE_DBC, SQL_HANDLE_STMT и SQL_HANDLE_DESC. Параметр hHandle используется для передачи идентификатора. Через параметр функции SQLGetDiagField передают номер записи заголовка, для которой извлекаются записи состояния. Это тот самый номер, что передается через одноименный параметр функции SQLGetDiagRec. Параметр nDiagId позволяет указать идентификатор извлекаемой записи состояния и задается в виде одной из предопределенных констант. С помощью параметра pDiagInfo Вы должны передать функции указатель на буфер, в которую будет записана диагностическая информация. Размер этого буфера задается параметром nBufferSize. Значение nBufferSize игнорируется в том случае, если указатель pDiagInfo ссылается на буфер данных фиксированного размера. Для текстовых строк допускается также указывать в параметре nBufferSize константу SQL_NTS. Она означает, что буфер содержит текстовую строку, закрытую двоичным нулем. И наконец, в переменную, адрес которой задается параметром pStringSize, записывается количество символов в извлеченном диагностическом сообщении (без учета двоичного нуля, закрывающего текстовую строку). Вот фрагмент программы, в котором для записи заголовка извлекаются записи состояния: rc = SQLGetDiagRec(nHandleType,
sqlhHandle, Здесь используются константы, перечисленные в таблице 10-19. Таблица 10-19. Идентификаторы типов данных C и ODBC
Программа ODBCAPP, исходные тексты которой мы описываем в этом разделе, выводит на консольный экран все записи из файла managers базы данных нашего Интернет-магазина: 1 | frolov | 123 |
Administrator | 21.12.1999 11:24:44 Полные исходные тексты программы ODBCAPP находятся в листинге 6-1. Листинг 10-7 Вы найдете в файле chap10\odbcapp\odbcapp.cpp на прилагаемом к книге компакт-диске. Глобальные определения и константы Для обращения к функциям и константам программного интерфейса ODBC мы включили в исходные тексты нашего приложения четыре файла: #include <sql.h> Для формирования строки сообщения об ошибке используется шаблон stirng из стандартной библиотеки шаблонов STL. Поэтому в исходном тексте мы сделали такие определения: #include <string> В области глобальных переменных задали следующие переменные: SQLHENV hEnv = SQL_NULL_HENV; В переменной hEnv хранится идентификатор среды исполнения, в переменной hDbc — идентификатор соединения с источником данных, а в переменной hStmt — идентификатор команды. Функция main выполняет инициализацию, установку соединения, создание и запуск команды, извлечение и вывод на экран результатов ее выполнения. В области локальных переменных функции main мы определили переменную rc, предназначенную для хранения кода возврата функций программного интерфейса ODBC, три строки, необходимые для подключения к источнику данных (содержащих имя источника данных, им пользователя и пароль), а также строку класса string для хранения сообщения об ошибке: RETCODE rc; Получив управление, функция main инициализирует среду выполнения программы, получая соответствующие идентификаторы: rc = SQLAllocHandle(SQL_HANDLE_ENV,
NULL, &hEnv); Обратите внимание, что пока мы не установили соединение с источником данных, обработка ошибок заключается в простом завершении программы с кодом 1. Дело в том, что на данном этапе средства расширенной диагностики ошибок еще не доступны. Далее программа устанавливает соединение с источником данных: rc = SQLConnect(hDbc, Если функция SQLConnect вернула код ошибки, мы вызываем функцию GetErrorMsg, определенную в нашей программе. О ней мы поговорим позже, а сейчас только скажем, что эта функция извлекает заголовки диагностических записей и формирует из них текстовую строку sErrMsg, которая затем отображается на консольном экране. В том случае, если функции main удалось открыть соединение с источником данных, она создает идентификатор команды и запускает команду на выполнение: rc = SQLAllocHandle(SQL_HANDLE_STMT,
hDbc, &hStmt); В качестве команды мы применили здесь простой оператор SELECT, извлекающий несколько полей из таблицы managers. Для обработки ошибочных ситуаций здесь вызывается функция GetErrorMsgConn. Она извлекает не только заголовки диагностических записей, но и поля записей состояния, формируя из этой информации строку сообщения об ошибке. Записи состояния становятся доступными только после установления соединения с источником данных, поэтому мы и подготовили две разные функции обработки ошибок. Следующий этап — привязка локальных переменных к полям набора записей, извлеченных в результате выполнения команды: SQLINTEGER nManagerID; Здесь мы последовательно привязываем пять локальных переменных nManagerID, szName, szPass, tsLastLogin, szRights к столбцам набора записей с именами ManagerID, Name, Password, LastLogin, Rights, соответственно. В этой главе мы уже рассказывали о том, как выполнить привязку данных с использованием функции SQLBindCol. После выполнения привязки функция main запускает цикл извлечения записей из набора, полученного в результате выполнения команды: while((rc = SQLFetch(hStmt)) !=
SQL_NO_DATA) Записи извлекаются средствами функции SQLFetch. В теле цикла мы выводим на консоль содержимое извлеченных полей. Так как поле LastLogin (дата последнего подключения сотрудника магазина) может содержать значения NULL, мы обрабатываем этот случай отдельно. Признаком извлечения пустой записи NULL является отрицательное значение переменной cbLastLogin, содержащей размер извлеченных данных. Освобождение ресурсов, полученных программой для обращения к базе данных, нужно выполнять следующим образом. Вначале программа освобождает идентификатор команды, вызывая для этого функцию SQLFreeHandle: SQLFreeHandle(SQL_HANDLE_STMT, hStmt); Далее выполняется отключение от источника данных при помощи функции SQLDisconnect: SQLDisconnect(hDbc); И наконец, мы освобождаем идентификаторы соединения и среды исполнения: SQLFreeHandle(SQL_HANDLE_DBC, hDbc); Эта функция выполняет извлечение заголовка диагностической записи, а также полей записей состояния, созданных для данной диагностической записи. Алгоритм извлечения записей мы уже рассматривали. Опустив для краткости определения локальных переменных, приведем исходный текст цикла извлечения записей и формирования сообщения об ошибке: while(rc != SQL_NO_DATA_FOUND) Заголовок диагностической записи извлекается функцией SQLGetDiagRec. Далее при помощи функции SQLGetDiagField извлекаются по очереди значения записей состояния. Среди них есть как численные значения, так и текстовые строки. Для формирования общей строки сообщения об ошибке мы преобразуем численные значения в строки и добавляем к строке sErrMsg, ссылка на которую передается функции GetErrorMsgConn. Вот какая строка формируется в том случае, если мы допустили синтаксическую ошибку в операторе SELECT, указав, например, его как SELECTT: SQLExecDirect Error Если же ошибка — в имени столбца, текст сообщения будет другим: SQLExecDirect Error Как видите, диагностика ошибки достаточно полная. Она вызывается для обработки ошибок, возникающих на ранней стадии работы программы до момента установления соединения с источником данных. Внутри этой функции находится цикл, в котором выполняется извлечение заголовки диагностических записей при помощи функции SQLGetDiagRec: while(rc != SQL_NO_DATA_FOUND) Эта функция также формирует в переменной sErrMsg итоговое сообщение об ошибке. Вот, например, какое сообщение появится на экране, если указать неправильное имя источника данных: SQLConnect error Как уже говорилось ранее, применение хранимых процедур позволяет упростить разработку и сопровождение проектов с базами данных за счет отделения программ от данных. Практически при создании приложений для Интернета или интрасетей Вам потребуется вызвать хранимые процедуры из серверных сценариев JScript или VB Script, встроенных в страницы ASP, либо из расширений сервера Web, таких, как программы CGI или приложения ISAPI. В последнем случае мы рекомендуем обращаться к базе данных Microsoft SQL Server с применением интерфейса ODBC, а не ADO или OLE DB. Именно поэтому, рассказывая о работе с методами доступа ADO и OLE DB в приложениях, написанных на C++, мы опустили материал о вызове хранимых процедур как второстепенный. Теперь же нам необходимо к нему вернуться, так как уже в следующей главе мы займемся созданием расширений сервера Web, обращающихся к базам данных через интерфейс ODBC. Запуск процедур выполняется примерно таким же образом, что и запуск команд при помощи функции SQLExecDirect. Вы должны сформировать команду в виде шаблона хранимой процедуры и затем запустить ее. Однако прежде чем рассказать о шаблонах хранимых процедур, мы займемся привязкой входных и выходных параметров, передаваемых процедуре при запуске. В ходе этой операции параметры процедуры привязываются к локальным переменным, определенным в программе. Для привязки параметров хранимых процедур Вы должны использовать функцию SQLBindParameter, прототип которой приведен ниже: SQLRETURN SQLBindParameter( Через параметр hStatement программа должна передать функции SQLBindParameter предварительно созданный идентификатор команды запуска процедуры. Параметр nParameter задает последовательный номер параметра процедуры, который будет привязан к локальной переменной. Нумерация параметров начинается с единицы. С помощью параметра nInputOutputType функции SQLBindParameter передается одно из следующих значений, определяющих направление передачи данных: SQL_PARAM_INPUT (входной параметр), SQL_PARAM_OUTPUT (выходной параметр) или SQL_PARAM_INPUT_OUTPUT (входной и выходной параметр). Параметр nValueType определяет идентификатор типа данных C локальной переменной, привязываемой к параметру. Здесь можно указывать такие константы, как SQL_C_CHAR или SQL_C_SSHORT. Полный список идентификаторов приведен в таблице 10-18. Тип параметра хранимой процедуры указывается через параметр nParameterType функции SQLBindParameter. Здесь указываются такие типы данных SQL, как SQL_CHAR или SQLSMALLINT (см. таблицу 10-18). Параметр nColumnSize определяет максимальное количество символов, цифр или точность данных, передаваемых через параметр. С помощью параметра nDecimalDigits программа задает количество десятичных цифр маркера параметра. Через параметр pParameterValue программа передает функции SQLBindParameter указатель на буфер локальной переменной, которая должна быть привязана к параметру хранимой процедуры. Длина этого буфера определяется параметром cbBufferSize. И наконец, через параметр pcbParamSize Вы передаете указатель на переменную, в которую предварительно была записана длина параметра. В следующем фрагменте кода мы выполняем привязку двух входных параметров и одного выходного параметра: SQLCHAR szAdminName[51]; Первый и второй параметры — входные. Они привязываются функцией SQLBindParameter с помощью константы SQL_PARAM_INPUT. Для третьего, выходного параметра мы указали константу SQL_PARAM_OUTPUT. Все наши параметры являются текстовыми строками. Локальные переменные, которые мы будем к ним привязывать, расположены в массивах символов типа SQLCHAR. Соответственно через четвертый и пятый параметры мы передаем функции SQLBindParameter константы SQL_C_CHAR и SQL_CHAR. Обратите внимание, как мы указываем количество символов в параметре (значение nColumnSize функции SQLBindParameter). Входные параметры предназначены для передачи имени пользователя и пароля, причем соответствующие столбцы в базе данных могут содержать до 50 символов. Выходной параметр предназначен для передачи строк, размером не более 16 символов. Последние три параметра функции SQLBindParameter описывают буферы, привязываемые к соответствующим параметрам. Они имеют одинаковый размер (51 символ с учетом двоичного нуля, закрывающего строку). Как мы уже говорили, для запуска на выполнение хранимых процедур можно воспользоваться уже знакомой Вам функцией SQLExecDirect. Ниже показан фрагмент кода, в котором запускается процедура с тремя параметрами: rc = SQLExecDirect(hStmt, Обратите внимание, что через второй параметр мы передали функции SQLExecDirect строку шаблона хранимой процедуры, в которой параметры отмечены символом «?». Помимо параметров процедура может возвращать значение. Для такой процедуры следует подготовить шаблон следующего вида: {? = call ProcName(?,?,?)} Напомним, что при выполнении привязки параметров хранимой процедуры функции SQLBindParameter необходимо указать номер привязываемого параметра nParameter. Если хранимая процедура возвращает значение, то для привязки локальной переменной к этому значению необходимо указать номер 1. При этом остальные параметры процедуры нумеруются, начиная со значения 2. При успешном запуске хранимой процедуры функция SQLExecDirect возвращает не только значения SQL_SUCCESS и SQL_SUCCESS_WITH_INFO но и SQL_NO_DATA. Код завершения SQL_NO_DATA означает, что при выполнении процедуры не был создан набор записей. В зависимости от того, какие действия выполняет хранимая процедура, данную ситуацию можно считать нормальной или ошибочной. Например, если процедура обновляет или удаляет записи в базе данных или в зависимости от тех или иных условий возвращает выходные параметры, не изменяя базу данных, набор записей может и не создаваться. Извлечение значений выходных параметров процедуры Перед извлечением значений выходных параметров хранимой процедуры (а также значения кода возврата процедуры) необходимо выполнить обработку наборов записей, созданных при выполнении команды. Если эти результаты не нужны, их можно проигнорировать, вызвав ее в цикле функцию SQLMoreResults: while((rc = SQLMoreResults(hStmt)) !=
SQL_NO_DATA) После завершения цикла, когда функция SQLMoreResults вернет значение SQL_NO_DATA, программа может получить выходные параметры из локальных переменных, к которым эти параметры были привязаны до запуска команды. Исходный текст программы ODBCPARAM Применение описанных выше методик вызова хранимых процедур с параметрами демонстрируется на примере консольной программы ODBCPARAM (листинг 10-8). Листинг 10-8 Вы найдете в файле chap10\odbcparam\ odbcparam.cpp на прилагаемом к книге компакт-диске. Программа ODBCPARAM запрашивает у пользователя идентификатор и пароль, выполняет запрос к таблице managers базы данных BookStore и затем отображает права пользователя: Login name: frolov Если пароль или идентификатор указаны неправильно, вместо прав на консоли появляется строка «nothing»: Login name: frolov Здесь мы не будем описывать глобальные определения и переменные программы ODBCPARAM, так как они аналогичны определениям, примененным в программе ODBCAPP (см. ранее в этой главе). Вместо этого мы сразу расскажем о функции main, выполняющей все основные действия. Сразу после запуска функция main получает все необходимые идентификаторы и открывает соединение с источником данных. Ниже показаны фрагменты кода, выполняющие эти операции: rc = SQLAllocHandle(SQL_HANDLE_ENV, NULL, &hEnv); Обработка ошибок опущена для краткости. Она выполняется точно таким же образом, как и в программе ODBCAPP. На следующем этапе мы запустим хранимую процедуру ManagerLogin, с которой Вы познакомились в четвертой главе нашей книги. Для удобства мы повторим исходный текст этой процедуры, немного изменив его: CREATE PROCEDURE ManagerLogin @User
varchar(50), @Pass varchar(50), @Rights varchar(16) output AS Здесь откорректированы значения, возвращаемого в случае отсутствия записи сотрудника в базе данных. Вместо пустой строки теперь возвращается строка «nothing». Как видите, процедура ManagerLogin имеет два входных и один выходной параметры. Получив управление, она проверяет существование записей в таблице managers. Если таблица пуста, в ней создается новая запись с правами администратора. Это нужно для начальной настройки системы при первом запуске. В ходе дальнейшей работы процедура ManagerLogin ищет в таблице managers запись для сотрудника магазина, идентификатор и пароль которого был переда ей через параметры @User и @Pass. Если такая запись найдена, права сотрудника переписываются в выходной параметр @Rights. Если же записи нет, в этой параметр записывается строка «nothing». Перед тем как запустить процедуру, нам нужно создать идентификатор команды и привязать три параметра, предназначенные для передачи имени, пароля и прав сотрудника. Создание идентификатора команды выполняется, как и раньше, функцией SQLAllocHandle: rc = SQLAllocHandle(SQL_HANDLE_STMT, hDbc, &hStmt); Далее программа вводит с консоли и привязывает к соответствующему параметру хранимой процедуры ManagerLogin строку szAdminName, содержащую имя сотрудника: SQLCHAR szAdminName[51]; Аналогичным образом выполняется ввод пароля и привязка переменной szAdminPass, предназначенной для хранения пароля: SQLCHAR szAdminPass[51]; В обоих случаях мы отмечаем входные параметры константой SQL_PARAM_INPUT. Выходной параметр привязывается с применением константы SQL_PARAM_OUTPUT: SQLCHAR szAdminRights[51]; К нему привязывается массив szAdminRights. Именно сюда будет записан результат работы хранимой процедуры ManagerLogin. Для запуска хранимой процедуры на выполнение мы вызываем функцию SQLExecDirect, передавая ей идентификатор команды и шаблон процедуры ManagerLogin: rc = SQLExecDirect(hStmt, После того как программа убедится в отсутствии наборов записей (что в нашем случае не требуется делать, так как процедура ManagerLogin не создает никаких наборов), она выводит консоль полученные права сотрудника: printf("\nYour rights: %s\n", szAdminRights); Перед завершением работы программа освобождает идентификатор команды, отключается от источника данных, а затем освобождает идентификаторы источника данных и среды исполнения: SQLFreeHandle(SQL_HANDLE_STMT, hStmt);
|
Библиотека
Братьев
Фроловых
Братьев
Фроловых